626 相邻id的人互换位置
1 | +---------+---------+ |
mysql存储引擎


MyISAM
读操作和插入操作为主 很少的更新和删除操作,并且对事务的完整性、并发性要求不是很高
MyISAM 的表又支持 3 种不同的存储格式,分别是:
1静态(固定长度)表; 静态表的数据在存储的时候会按照列的宽度定义补足空格,但
是在应用访问的时候并不会得到这些空格,如果需要保存的内容后面本来就带有空格,那么在返
回结果的时候也会被去掉.
2动态表; 是频繁地更新删除记录会产生碎片,需要定期执行 OPTIMIZE TABLE 语句或 myisamchk -r 命令来改善性能
3压缩表。
innodb
自增长列 外键
InnoDB 存储表和索引有以下两种方式。
1 使用共享表空间存储,这种方式创建的表的表结构保存在.frm 文件中,数据和索引
保存在 innodb_data_home_dir 和 innodb_data_file_path 定义的表空间中,可以是
多个文件。
2 使用多表空间存储,这种方式创建的表的表结构仍然保存在.frm 文件中,但是每个
表的数据和索引单独保存在.ibd 中。如果是个分区表,则每个分区对应单独的.ibd
文件,文件名是“表名+分区名”,可以在创建分区的时候指定每个分区的数据文件
的位置,以此来将表的 IO 均匀分布在多个磁盘上。
即便在多表空间的存储方式下,共享表空间仍然是必须的,InnoDB 把内部数据词典和未
作日志放在这个文件中。
memory
MEMORY 存储引擎使用存在内存中的内容来创建表。每个 MEMORY 表只实际对应一个
磁盘文件,格式是.frm。MEMORY 类型的表访问非常得快,因为它的数据是放在内存中的,
并且默认使用 HASH 索引,但是一旦服务关闭,表中的数据就会丢失掉。
可以指定使用 HASH 索引还是 BTREE 索引
使用唯一索引
索引的列的基数越大,索引的效果越好。
存放出生日期的列具有不同值,很容易区分各行。而用来记录性别的列,只含有“ M”
和“F”,则对此列进行索引没有多大用处,因为不管搜索哪个值,都会得出大约一半的行。
explain key_len 计算方法
原来数据类型长度+使用变长字段需要额外增加2个字节,使用NULL需要额外增加1个字节
索引左前缀
在创建一个 n 列的索引时,实际是创建了 MySQL 可利用的 n 个索引。
多列索引可起几个索引的作用,因为可利用索引中最左边的列集来匹配行。这样的列集称为
最左前缀。
比如:索引index1:(a,b,c)有三个字段
走index1索引:1
2
3
4
5select * from table where a = '1'
select * from table where a = '1' and b = ‘2’
select * from table where a = '1' and b = ‘2’ and c='3'
特殊情况说明下,select * from table where a = '1' and b > ‘2’ and c='3'这种类型的也只会有a与b走索引,c不会走。
像select * from table where a = '1' and b > ‘2’ and c='3' 这种类型的sql语句,在a、b走完索引后,c肯定是无序了,所以c就没法走索引,数据库会觉得还不如全表扫描c字段来的快。
Fulltext 索引主要用来替代效率低下的 LIKE ‘%***%’ 操作
Fulltext 索引主要用来替代效率低下的 LIKE ‘%***%’ 操作
BTREE 索引与 HASH 索引
HASH 索引:
1 只用于使用=或<=>操作符的等式比较。
2 优化器不能使用 HASH 索引来加速 ORDER BY 操作。
3 MySQL 不能确定在两个值之间大约有多少行。如果将一个 MyISAM 表改为 HASH 索
引的 MEMORY 表,会影响一些查询的执行效率。
4 只能使用整个关键字来搜索一行。
BTREE 索引,当使用>、<、>=、<=、BETWEEN、!=或者<>,或者 LIKE ‘pattern’(其
中’pattern’不以通配符开始)操作符时,都可以使用相关列上的索引。
例如
索引字段进行范围查询的时候,只有 BTREE 索引可以通过索引访问:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15SELECT * FROM t1 WHERE key_col > 1 AND key_col < 10;
SELECT * FROM t1 WHERE key_col LIKE 'ab%' OR key_col BETWEEN 'lisa' AND 'simon';
explain SELECT * FROM city WHERE country_id > 1 and country_id < 10 \G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: city
type: range
possible_keys: idx_fk_country_id
key: idx_fk_country_id
key_len: 2
ref: NULL
rows: 24
Extra: Using where
1 row in set (0.00 sec)
HASH 索引实际上是全表扫描的:
1 | mysql> explain SELECT * FROM city_memory WHERE country_id > 1 and country_id < 10 \G |
INET_ATON INET_NTOA
INET_ATON(IP)和 INET_NTOA(num)函数主要的用途是将字符串的 IP 地址转换为数字表示的网
络字节序,这样可以更方便地进行 IP 或者网段的比较。
“192.168.1.3”和“192.168.1.20”之间一共有多少 IP 地址:
1 | select * from t |
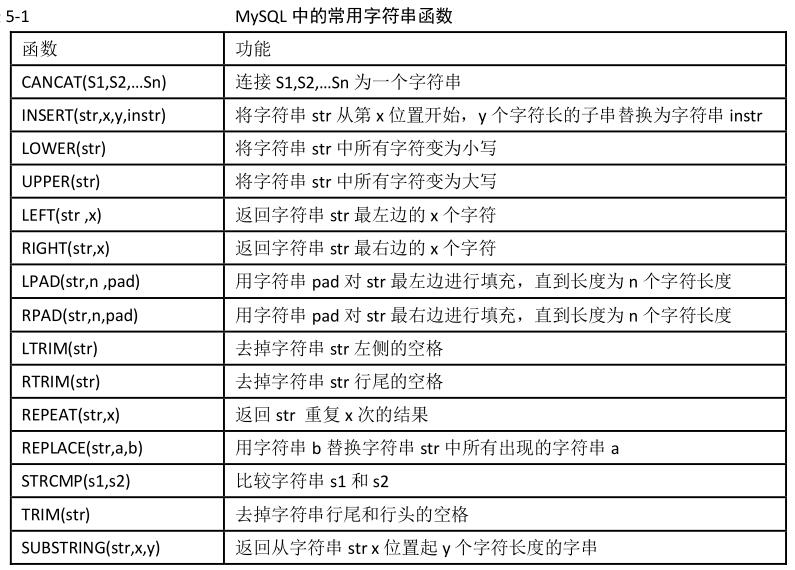
常用字符串函数
!!!176 第二大 limit offset
1 | SELECT MAX(Salary) as SecondHighestSalary |
如果只有一条数据 下面代码不行1
2
3select distinct Salary as SecondHighestSalary
from Employee
order by Salary desc limit 1 offset 1;
196 !!!删除重复的emails
select and update conflictdelete from Person where id not in(select min(id) as id from Person group by email)
错误 You can’t specify target table ‘Person’ for update in FROM clause
正确做法:1
2
3
4
5delete from Person where id not in(
select t.id from (
select min(id) as id from Person group by email
)as t
);
1 | delete p2 from Person p1 ,Person p2 |
时间日期函数

!!! 197 TO_DAYS找到比前一天温度高的天 按日期列排序
DATEDIFF1
2SELECT w1.Id FROM Weather w1, Weather w2
WHERE w1.Temperature > w2.Temperature AND DATEDIFF(w1.Date, w2.Date) = 1;
Subdate1
2SELECT w1.Id FROM Weather w1, Weather w2
WHERE w1.Temperature > w2.Temperature AND SUBDATE(w1.Date, 1) = w2.Date;
TO_DAYS1
2SELECT w1.Id FROM Weather w1, Weather w2
WHERE w1.Temperature > w2.Temperature AND TO_DAYS(w1.Date) = TO_DAYS(w2.Date) + 1;
(student,class)表中找学生数>=5的课程
1 | SELECT |
183 NOT IN 在order表(id,customerid)中找到没买过东西的用户
1 | select Name as Customers |
175 拼接有1列相同的两张表 using , natural left join
1 | select FirstName,LastName, City, State |
1 | SELECT FirstName, LastName, City, State |
1 | select FirstName,LastName, City, State |
181 根据领导id列找到比领导拿前多的人join on
?为什么group by那么快1
2
3
4
5
6
7
8
9
10
11select E1.Name as Employee
from(
select * from Employee
)E1
left join
(
select * from Employee
group by id
)E2
on E1.ManagerId = E2.Id
where E1.Salary > E2.Salary
182找出重复的 group by和having
1 | select Email from Person |
去重 select distinct Email from Person;
mod 用法
1 | SELECT * |
流程函数
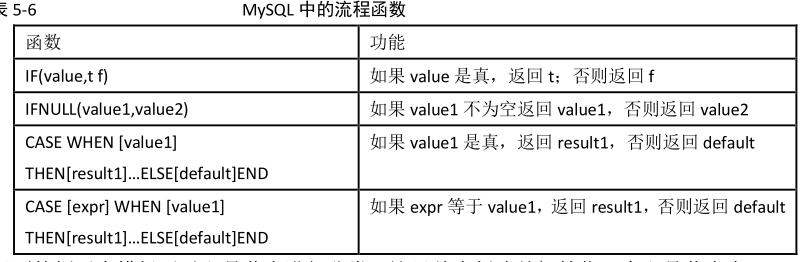
ifnull替换空值1
select ifnull(salary,0) from salary;
case when
1 | select |
更新交换字段
1 | update salary set |
union 比 or 快
1 | SELECT name, population, area |
比2个or快
using UNION ALL is much faster than UNION since we don’t need to sort the result.
Given that MySQL usually uses one one index per table in a given query, so when it uses the 1st index rather than 2nd index, it would still have to do a table-scan to find rows that fit the 2nd index.
有哪些清空表的方式?
正确答案: A B C 你的答案: A C D (错误)
A.drop表然后重建
B.truncate表
C.delete表
D.update表
常用的分析函数有哪些
正确答案: A B C 你的答案: B (错误)
A.row_number()
B.rank()
C.dense_rank()
D.mix_rank()
取前价最高的top100商品,需要用到哪些函数组合?
正确答案: A B C 你的答案: A C (错误)
A.order by
B.group by
C.limit
D.max
全文检索
MyISAM和InnoDB,前者支持全文本搜索,而后者不支持。
cross join
以下数据表连接正确的有?
正确答案: A B C D 你的答案: A B C (错误)
A.join
B.left join
C.right join
D.cross join
Cross Join.From A cross join B is produces the cartesian product A × B. Each A will be repeated once for every B. If A has 100 rows and B has 100 rows, the result set will consist of 10,000 rows.
Having
HAVING非常类似于WHERE。事实上,目前为止所学过的所有类型的WHERE子句都可以用HAVING来替代。唯一的差别是WHERE过滤行,而HAVING过滤分组。
Uinon & Union all
在数据库的SQL语言开发中,下述关于Union和Union all的描述哪些是正确的:
正确答案: A B D 你的答案: B C D (错误)
A 使用Union或Union all组合查询的数据集,需满足两个条件:
列数和列的顺序必须相同;数据类型必须兼容
B.Union在进行表链接后会筛选掉重复的记录,所以在表链接后会对所产生的结果集进行排序运算,删除重复的记录再返回结果。
C.Union all返回的结果集就会包含重复的数据了,如果表数据量大的话可能会导致用磁盘进行排序。因此,从效率上说,union要比union all快很多
D.如果可以确认合并的两个结果集中不包含重复的数据的话,那么就建议使用Union all
Union:
UNION中的每个查询必须包含相同的列、表达式或聚集函数
truncate
下面关于TRUNCATE 和DELETE 的说法正确的是
正确答案: C D 你的答案: A C (错误)
A.TRUNCATE 属于DDL,而DELETE 属于DML
B.TRUNCATE 与DELETE 均能够删除表中的指定记录
C.TRUNCATE 不能删除表中指定的记录,而DELETE 能够删除表中的指定记录
D.在清空表记录的操作时,TRUNCATE 的执行效率比DELETE 高
关于delete与truncate 区别:
delete和truncate table的最大区别是delete可以通过WHERE语句选择要删除的记录。但执行得速度不快。而且还可以返回被删除的记录数。而truncate table无法删除指定的记录,而且不能返回被删除的记录。但它执行得非常快。
C:DELETE 语句每次删除一行,并在事务日志中为所删除的每行记录一项。TRUNCATE TABLE 通过释放存储表数据所用的数据页来删除数据,并且只在事务日志中记录页的释放。
TRUNCATE TABLE 删除表中的所有行,但表结构及其列、约束、索引等保持不变。
D:TRUNCATE TABLE 在功能上与不带 WHERE 子句的 DELETE 语句相同:二者均删除表中的全部行。但 TRUNCATE TABLE 比 DELETE 速度快,且使用的系统和事务日志资源少。
范式
以下哪一个不是对数据库关系范式的目的?
正确答案: B 你的答案: B (正确)
A减少数据冗余
B加快查询速度
C解决更新异常问题
D提高存储空间效率
非主属性非部分依赖于主关键字,这个是哪个范式的定义
正确答案: B 你的答案: B (正确)
A1NF
B2NF
C3NF
第三范式 不存在 传递函数依赖关系 名字可以决定分类;分类可以决定分类描述 则存在非关键字段 分类描述 对名称的依赖
在关系数据库系统中,为了简化用户的查询操作,而又不增加数据的存储空间,常用的方法是创建
正确答案: C 你的答案: C (正确)
A另一个表(TABLE)
B游标(CURSOR)
C视图(VIEW)
D索引(INDEX)
QPS TPS
mysql当前一个sql语句只能用到一个cpu
qps:每秒查询量
并发量会使cpu连接数占满
1000Mb/8 = 100MB 的网卡 减少从服务器 减少主从同步
但表超过千万行 or 表数据文件超过10G
mysql<5.5 建立索引会锁表。>=5.5不锁表但是会主从延迟
DDL操作:create、alert、drop、index、syn、cluster 修改表结构的操作
mysql主从复制是单线程。大表修改在从服务器上没有完成。其他操作都不能执行。
大事务:
windows xp 默认tcp并发数只有10
QPS是每秒处理的sql数量,而40个cpu同时并发处理40个sql是指纳秒级的
web应用核心数量比主频更重要。
MyISAM 索引在内存中,数据通过操作系统缓存。
InnoDB 同时在内存中缓存数据和索引。
缓存可以把浏览量计数器很多次先写到缓存,再一批存到磁盘。
开启mysql查询日志
https://blog.csdn.net/leshami/article/details/397792251
2
3
4
5
6
7
8
9
10
11
12
13
14
15show variables like '%general%';
+------------------+------------------------------+
| Variable_name | Value |
+------------------+------------------------------+
| general_log | ON |
| general_log_file | /var/lib/mysql/localhost.log |
+------------------+------------------------------+
set @@global.general_log=1;
cat /var/lib/mysql/localhost.log
/usr/sbin/mysqld, Version: 5.6.41 (MySQL Community Server (GPL)). started with:
Tcp port: 3306 Unix socket: /var/lib/mysql/mysql.sock
Time Id Command Argument
180905 18:24:55 5 Query select id,name from poi where lng between 116.3284 and 116.3296 and lat between 39.9682 and 39.9694
180905 18:26:00 5 Query show variables like '%general%'
180905 18:28:44 5 Query select * from poi where 1=1
mybatis逆向工程generatorConfig.xml
explain执行计划 :select,update,insert,replace,delete
分区
show plugins;
可以看到partition 则可以分区。逻辑上一个表,物理上多个文件中。
在create table的最后加上partition by hash(id) partitions 4.frm存储表数据.ibdinndb数据文件
分区之后.ibd会有好几个
hash分区 利用表中的int列或者by hash(UNIX_TIMESTAMP(login_time))将timestamp转成int
range分区 log推荐使用 日期/时间 查询的时候包含分区键 适合定期清理历史数据1
2
3
4partition by range(id)(
partition p0 values less than(10000),
partition p1 values less than(20000),
partition p3 values less than maxvalue);
list分区 按枚举1
2
3partition by list(type)(
partition p0 values in (1,3,5,7,9),
partition p1 values in (2,4,6,8));
到了新的一年添加分区1
alter table t1 add partition (partition p4 values less than(2018));
删除分区1
alter table t1 drop partition p0;
归档新建一个和t1结构相同的 非分区表t2 .一般迁移后删除分区,切换归档表的存储引擎
分区表只能查询不能写 分区表梗适合用mysam引擎1
2
3alter table t1 exchange partition p0 with table t2;
#--drop之后切换引擎
alter table t2 ENGINE=ARCHIVE;
password用char(32)timestamp on update CURRENT_TIMESTAMP字段会在表被修改时自动更新
Mybatis
- mybatis-3-config.dtd: 可以用
<properties>导入配置文件
在<mappers>里可以用<package>导入整个有mapper.xml的文件夹 - mybatis-3-mapper.dtd
<typeAliases>中添加<package>自动扫描包,将类名作为别名
PageHelper.orderBy("price desc")按价格降序(sql中的order by 之后的格式)
mysql like通配符
% 任意多个字符
ER图
矩形:实体
特化:自顶向下继承设计
概化:底向上
菱形:联系集:把多对多变成1对多 用虚线连接联系集的属性
双线:全参与:表示在联系集中的参与度<advisor>=student表示每个学生都要有导师,
双边菱形:表示弱实体集和它依附的实体集。当弱实体集里放入依赖的实体集的id,则不需要联系集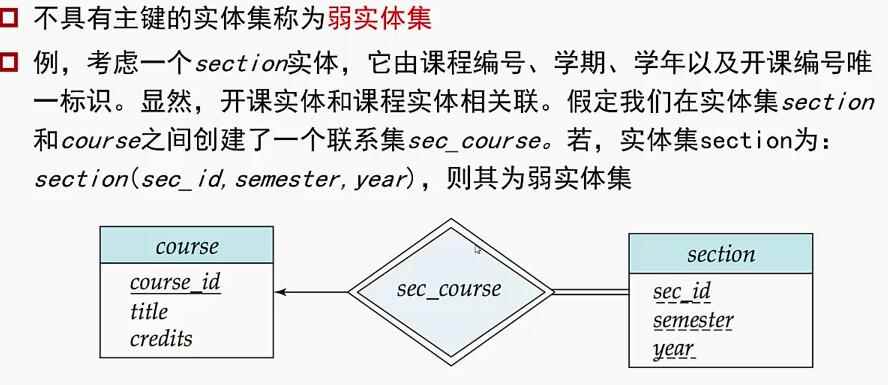
椭圆:属性
角色:<先修课联系集>和[课程]的联系通过course_id和prereq_id角色标识区分
派生属性:可以通过其它属性计算得到
复合型属性应该拆分成2个属性
多值型(一个老师对应多个电话)应该用另一个(id,phone)(1,phone1)(1,phone2)每个属性映射到单行
映射基数:1:1,1:n,n:1,n:n
基数约束:导师<-<advisor>-学生
一对一:箭头从关系指向实体:导师<-<advisor> 一名学生只有一名导师
一对多:没有箭头表示多端,有箭头表示“一”端 <advisor>-学生 一名老师可以有多名学生。导师 0..* <advisor> 1..1 学生 参与的上限..下限,0表示老师参与的下线是0,不是全参与,是半参与。
天然的三元关系 导师 项目 学生 通过一个联系集不能拆分成2个二元关系。
- 什么时候作为实体:instructor/ins-phone/phone三张表什么时候作为属性instructor(phone)
- 只对名字和单值(不是多值(对应多个电话))感兴趣则为属性:性别。
- 一个对象除了名字意外,还有其它属性要描述则定义成实体:电话、住址、部门。
是实体集还是用联系集(对象之间的动作):考虑映射的基数
customer-<loan>-branch 但是当要表示一个客户在一个银行里多笔贷款
customer-<borrow>-loan(实体)-<Loan-bra>-branch
客户与贷款多对多,贷款对支行一对多。用属性student(supervisior-id,supervisior-name)还是用联系集
<stu-sub>,<stu-class>
innodb有索引组织表
IP地址字符串转intINET_ATON('255,255,255,255')=4292967295(无符号int最大值)INET_NTOA('4292967295')=’255,255,255,255’Varchar(255)utf-8汉字3个字节 总共765字节
避免使用TEXT64k,BLOB 可以用varchar mysql内存映射表不持支,所以排序只能用磁盘映射表
timestamp只能存到2038年01-19
decimal精确浮点类型
预编译语句 每次执行只需要传递参数 节省带宽1
2
3
4
5prepare stmt1 from 'select sqrt(pow(?,2)+pow(?,2)) as hypotenuse';
set @a=3;
set @b=4;
execute stmt1 using @a,@b;
deallocate prepare stmt1
将where date(ctime)="20160901"改成where ctime>='20160901 and ctime<'20160902可以使用索引
范围查询会使联合索引失效 要把范围查询的表放到索引右侧
使用leftjoin/not exists代替 not in(会使索引失效
索引列的循序 区分度(列中唯一值数量/总行数)高的放在联合索引左边
不使用外键 外键用于数据参照完整性(数据一致性)但是降低写性能,可以用其它方式保证一致性 但是要在表之间的关联键上建立索引
慢查询
开启慢查询日志 SQL监控1
show variables like 'slow_query_log';
记录没有使用索引的sql
log_queries_not_using_indexes 变量1
2
3show variables like '%log%';
set global log_queries_not_using_indexe=on;
set long_query_time = 1;
long_query_time超过多少秒之后的查询记录在日志中
查看慢查询日志的位置1
show variables like 'slow%';
慢查询分析工具mysqldumpslow
count(1)和count(*)和count(*)
count(1)比count(*)效率高一些1
2
3create table t(id int);
insert into t value(1),value(2),(null);
select count(*),count(id),count(1) from t;
count(*) |
count(id) |
count(1) |
|---|---|---|
| 3 | 2 | 3 |
内置类型
now()
数据类型
int(11)和int(21)都占4个字节,区别在于补零位数1
2
3create table t(a int(11) zerofill, b int(21) zerofill);
insert into t values (1, 1);
select * from t;char和varchar存储字符数。- char 存储255个字符,varchar根据类型计算字符数,上限是65535个字节
- char会自动补空,varchar<=255用一个字节>255用两个字节存储长度length
desc 查看表结构
mysql join
inner join内连接,两张表的公共部分 数据库会先在每个表里先查条件再生成笛卡儿积select a.name from a A inner join b B on A.name =B.name;left outer join左外连接,以左表为基础 内链接当左表中查询条件是null的时候被忽略,外连接则有
用左外连接查询只存在A中不存在B中的where B.Key is NULL (优化not in不会使用索引)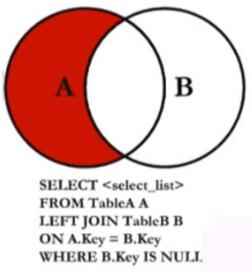
select * from b left outer join a on a.name =b.name where a.Id is null;right outer joinselect * from a right outer join b on a.name =b.name where a.Id is null;full join
count(*),min(p.'price') group by p."id","name"
数据库
Myisam表锁 -> Innodb 行锁 从大锁到小锁提升并行度
MyISAM引擎不持支事务,优点是读写快,列存储5.5之前的默认
Innodb支持事务ACID 行级锁,高并发场景好
JDBC
static final String JDBC_DRIVER="com.mysql.jdbc.Driver";- close放在finally里,保证执行
- 防止空指针异常
1
2
3
4
5finally{
if(conn!=null)conn.close();
if(stmt!=null)stmt.close();
if(rs!=null) rs.close();
}
游标:读取记录太多,内存放不下。DB_URL:
useCursorFetch=true1
static final String DB_URL ="jdbc:mysql://localhost/scraping?characterEncoding=utf8&useCursorFetch=true&useSSL=true";
ptmt=conn.prepareStatement(sql);
每次从服务器端取回记录的数量ptmt.setFetchSize(1);
rs = ptmt.executeQuery();
- 流方式:记录中存在大字段内容:博文。读一条记录内存可能放不下。
变成二进制流读取小区间InputStream in = ResultSet.getBinaryStream("blog")- 在外部生成一个文件,每次读取一行输出到外部文件
1
2
3
4
5
6
7File f = new File(FILE_URL);
OutputStream out = null;
out = new FileOutputStream(f);
int tmp = 0;
while((tmp= in.read)!==-1)out.write(tmp);
in.close();
out.close();
连接池
DriverManager.getConnection流程
客户端利用密码种子和自己保存的数据库密码按加密算法得到加密密码
- 每个线程使用数据库连接后不销毁,每个请求从连接池中【租借】连接
- 数据库服务器端处理请求时要分配资源,请求结束后被释放。服务器设置最大并发连接数。抛toomanyConnection异常。应在客户端中实现业务线程排队获取数据库连接。
DBCP
是一组jar包:commons-dbcp,jar,commons-pool.jar,commons-logging.jar
dbcp重写了Connection的close方法,把销毁数据库连接改成了归还给连接池
1
2
3
4
5
6
7
8public static void dbpoolInit(){
db = new BasicDataSource();
db.setUrl(DB_URL);
db.setDriverClassName(JDBC_DRIVER);
db.setUsername(USER);
db.setPassword(PASSWORD);
db.setMaxTotal(2);
}优化连接池
- 提高第一次访问数据库的速度,在连接池中预制一定数量的连接
.setInitialSize(1) .setMaxTotal()设置客户端的最大连接数,超过的不创建新连接,而是进入等待队列.setMaxWaitMillis()设置最大等待时间.setMaxIdel()空闲连接数的最大值,超过则销毁setMinIdel()空闲数低于则创建,建议于MaxIdel相同
- 提高第一次访问数据库的速度,在连接池中预制一定数量的连接
- DBCP定期检查,服务端会自动关闭空闲连接,连接池可能租借失效的连接
- 定期检查连接池中连接的空闲时间 开启
.setTestWhileIdel(True) - 应该销毁的最小空闲时间
.setMinEvictableIdleTimeMillis() - 检查的时间间隔,应小于服务器自动关闭连接的时间(Mysql 8小时)
.setTimeBetweenEvictionRunsMillis()
- 定期检查连接池中连接的空闲时间 开启
- Mysql
show processlist;查看连接数
防范SQL注入'--
参数化sql
conn.prepareStatement(sql)传入格式化sql,需要传入的参数用?占位1
Select * from user where userName = ? And password=?
传入参数
ptmt.setString(1,username)参数位置从左往右1开始- 数据库权限、封装数据库异常
- mysql
AES_ENCRYPT/AES_DECRYPTstring加密/解密
事务:单个逻辑工作单元执行的一系列操作,逻辑工作单元满足ACID(原子、一致、隔离、持久) ,并发控制的基本单位。
1 | try{ |
检查点
1 | Savepoint sp = Connection.setSavepoint(); |
事务的隔离级别
- 脏读:一个事务读取了一个事务未提交的更新

- 不可重复读:同一个事务,两次读取值不一样。
- 幻读:同一个事务,两次读取行记录数目不一样。插入了新记录

| 隔离级别 | 脏读 | 可重复读 | 幻读 |
|---|---|---|---|
| 读未提交 | √ | X | √ |
| 读提交 | X | X | √ |
| 可重复读 | X | √ | √ |
| 串行化 | X | √ | X |
- 读未提交:允许脏读
- 读提交:不允许脏读,可以不可重复读
重复读:可能出现幻读。 MySQL的事务隔离级别。
1
set
串行化:最高隔离级别,所有事务串行执行,不能幻读。
- 设置和获取事务隔离级别
1
2Connection.getTransactionIsolation()
Connection.setTransactionIsolation()
MySQL的锁
- 排他锁X:与任何锁都冲突,等待。(写锁)
- 共享锁S:多个事务共享一把锁。其它事务不会被阻塞。(读锁)
加锁方式 - 外部加锁:SQL语句
- 共享
select * from table lock in share mode - 排他
select * from table for update
- 共享
- 内部自动加锁
- 加锁粒度和策略:表锁table lock:开销少;行锁(row lock): innoDB
MySQL所有的select读都是快照读。存储引擎Innodb实现了多版本控制(MVCC),不加锁快照读。
所以一个事务内部保证select数据一致要外部加锁
- MVCC 在每行记录后面保存两个隐藏的列:行创建时间,过期时间。通过版本号记录时间,每开始新的事务,系统版本递增。
- Update 对行加排他锁X
- 分析MySQL处理死锁:
show engine innodb status
Mybatis 底层基于JDBC
- SqlSessionFactory实例能将对象操作转换成数据库操作
事务管理器transactionManager type = "jdbcdataSource驱动、url、用户名、密码 - 对象类、操作接口
- 映射文件
<mapper namespace = "操作接口"> - 将映射文件加载到配置文件
<mappers><mapper resource=""> - 测试
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21public static void main(String[] args) {
// 1. 声明配置⽂文件的⺫⽬目录渎职
String resource = "confAnnotation.xml";
// 2. 加载应⽤用配置⽂文件
InputStream is = HelloMyBatisAnnotation.class.getClassLoader().getResourceAsStream(resource);
// 3. 创建SqlSessonFactory
SqlSessionFactory sessionFactory = new SqlSessionFactoryBuilder()
.build(is);
// 4. 获取Session
SqlSession session = sessionFactory.openSession();
try {
// 5. 获取操作类(接口)
GetUserInfo getUserInfo = session.getMapper(GetUserInfo.class);
// 6. 完成查询操作
User user = getUserInfo.getUser(11);
System.out.println(user.getId() + " " + user.getUserName() + " " + user.getCorp());
} finally {
// 7.关闭Session
session.close();
}
}
- 在操作接口上用注解@select
ResultMap
- 构造方法 mapper.xml
1
2
3
4
5
6
7
8
9
10
11<resultMap id="UserMap" type="com.micro.profession.mybatis.resultMapTest.User">
<constructor>
<idArg column="userId" javaType="int" />
<arg column="userName" javaType="String" />
<arg column="corp" javaType="String" />
</constructor>
<collection>
<association>
</association>
</collection>
</resultMap>