https://github.com/randian666/algorithm-study
https://www.nowcoder.com/discuss/50571?type=2&order=0&pos=21&page=2
https://github.com/xuelangZF/CS_Offer/blob/master/Linux_OS/Signal.md
http://www.linya.pub/
https://www.nowcoder.com/discuss/50571?type=2&order=0&pos=21&page=2
https://www.nowcoder.com/discuss/111311
架构扫盲
https://github.com/doocs/advanced-java
Spring
Spring 里单例中的prototype和prototype中的单例
一个作用域为Singleton的Bean(设为A)依赖于一个作用域为prototype的Bean(设为B)。由于A是单例的,只有一次初始化的机会,它的依赖关系也只在初始化阶段被设置,但它所依赖的B每次都会创建一个全新的实例,这将使A中的B不能及时得到更新。这样将导致如果客户端多次请求A,并调用A中B的某个方法(或获取A中B的某个属性),服务端总是返回同一个B,但客户端直接请求B却能获得最新的对象,这就产生了对象不同步的情况。
办法有二:
部分放弃依赖注入:当A每次需要B时,主动向容器请求新的Bean实例,即可保证每次注入的B都是最新的实例。
利用方法注入。<lookup-method>标签@Lookup注解
1 |
|
com.spring.springlearn.A$$EnhancerBySpringCGLIB$$1b52cac0@6f330eb9 com.spring.springlearn.A$$EnhancerBySpringCGLIB$$1b52cac0@6f330eb9
B in A: com.spring.springlearn.B@341a8659
B in A: com.spring.springlearn.B@4943defe
com.spring.springlearn.B@5eefa415 com.spring.springlearn.B@181d7f28
A in B: com.spring.springlearn.A$$EnhancerBySpringCGLIB$$1b52cac0@6f330eb9
A in B: com.spring.springlearn.A$$EnhancerBySpringCGLIB$$1b52cac0@6f330eb9
Spring里面的单例是怎么线程安全的prototype
Spring对一些(如RequestContextHolder、TransactionSynchronizationManager、LocaleContextHolder等)中非线程安全状态的bean采用ThreadLocal进行处理,让它们也成为线程安全的状态,因此有状态的Bean就可以在多线程中共享了。
BeanFactory和FactoryBean的区别
BeanFactory是IOC容器的接口。
FactoryBean工厂Bean是一个接口,是适配器。简单工厂模式和装饰模式。
当类无法new创建实例的时候,如静态工厂访问的bean,可以作为其它bean的工厂。
当在IOC容器中的Bean实现了FactoryBean后,通过getBean(String BeanName)获取到的Bean对象并不是FactoryBean的实现类对象,而是这个实现类中的getObject()方法返回的对象。
直接访问FactoryBean的实现类,就要getBean(&BeanName),在BeanName之前加上&。
用法:
继承这个接口的Bean,里面有个成员对象是目标bean,用InitializingBean接口的afterPropertiesSet中给这个成员对象用静态工厂方法创建实例。再getObject中返回这个实例。
事务如何保证多次获取到是同一个连接 如何保存Connection
bindResource key是DataSource,value是连接保存在ThreadLocal
事务的隔离级别
1.default底层数据库的默认级别
2.读未提交 3.已提交4.可重复读5.串行化
事务的传播行为
1.require,支持一个已经存在的事务。如果没有事务,开一个新事务
2.supports,支持一个已经存在的事务。如果没有事务,则以非事务方式执行
3.mandatory,支持一个已经存在的事务。如果没有活动事务,抛出异常。
4.requires_new,始终开始新的事务。如果活动事务已经存在,将其暂停。
5.not_supported,不支持活动事务,始终以非事务方式执行,并暂停现有事务。
6.never,即使存在活动事务,始终以非事务方式运行,如果存在活动事务抛出异常。
7.nested,如果存在活动事务,嵌套事务中运行,如果没有和required一样。
Mybatis
resultmap和resulttype的区别
使用resultType进行输出映射,只有查询出来的列名和pojo中的属性名一致,该列才可以映射成功。只要查询出来的列名和pojo中的属性有一个一致,就会创建pojo对象。
如果查询出来的列名和pojo的属性名不一致,通过定义一个resultMap对列名和pojo属性名之间作一个映射关系。
<<<<<<< HEAD
mybatis缓存在哪
一级缓存是 SqlSession,二级缓存是mapper级别缓存。
缓存在哪
一级缓存SqlSession级别
二级缓存mapper级别 可能不在内存
refs/remotes/origin/hexo-edit
和jdbc的区别
如何防止sql注入
Http
Http如何控制超时
post和get的区别 安全性
JVM
分配堆内存怎么保证线程安全
1.TLAB
为了保证Java对象的内存分配的安全性,同时提升效率,每个线程在Java堆中可以预先分配一小块内存,这部分内存称之为TLAB(Thread Local Allocation Buffer),这块内存的分配时线程独占的,读取、使用、回收是线程共享的。
可以通过设置-XX:+/-UseTLAB参数来指定是否开启TLAB分配。
2.CAS和失败重试的方式保证更新操作的原子性
代理模式
实现延迟加载,封装 xml读取、数据库连接等初始化操作,初始化加载代理类代理类什么都不做。
真的需要数据库查询再加载数据库连接。
队列
LinkedBlockedQueue是2个锁
ThreadLocal内存泄漏
内存屏障
Spring的类加载器
G1的过程
Java
反射修改字符串不产生新的对象!
1 | Field f = String.class.getDeclaredField("value"); |
如何用自己的String替换掉JDK的String
== equals hashcode的联系
== 栈中的值进行比较的
equals是==
hashcode
.class和getClass()的区别
.class编译时确定,getclass()运行时根据实际实例确定。1
2
3F a = new C();
a.getClass().getName();// C
a.class.getName(); //F
ES怎么保证一致性
协调节点路由请求到主分片,成功写入所有副本后再返回成功
每个写操作会有seq_no序号
ES有一个全局检查点:是所有已经对其的序号,主分配推荐全局检查点,一旦所有副本都超出给定序号,更新全局检查点。副本维护本地检查点。
写一致的默认策略是quorum,多数分片,可以是主/副分片。
优化加大translog flush间隔。加大index refresh 1s间隔:降低segment merge频率,refresh会产生新的lucene段。如果不要那么实时性。
1.数据库
SQL生命周期:
应用服务器与数据库服务器建立一个连接
数据库进程拿到请求sql
解析并生成执行计划,执行
读取数据到内存并进行逻辑处理
通过步骤一的连接,发送结果到客户端
关掉连接,释放资源
数据库连接池
1.数据库更适合长连接,复用连接,维护连接对象、分配、管理、释放,也可以避免创建大量的连接对DB引发的各种问题
2.通过请求排队缓解对db的冲击
mysql 的其他引擎
设计数据库表
1.数据库里的乐观锁和悲观锁
共享锁、排他锁
悲观锁:select ... for update;
主键明确&有结果行锁,无结果集(查空)无锁。
查询无主键或者不走索引where id<>'66' like,表索 。
乐观锁:数据库version字段
2.索引什么时候会失效:模糊匹配、类型隐转、最左匹配
1)有or or中的每个列都要有索引
2)like 以%开头
用覆盖索引index_all 只访问索引的查询
using index & using where:
查找使用了索引,但是需要的数据都在索引列中能找到,所以不需要回表查询数据
例如联合索引a,b一般不能单独用b的索引,但是count就能用
3)如果where=字符串 一定要加引号
4)如果数据太少还是全表扫描快就不用,如果查询的列太多,数据太多,会直接走主键全表扫描
5)is null或者is not null
3.Mysql 有哪些索引
数据结构:B+,hash,全文索引,R-Tree
物理存储:聚集索引、非聚集索引
逻辑角度:主键、单列索引、多列索引、空间索引、覆盖索引(?)
4.数据库隔离级别
5.mybatis和jdbc比有什么好处
1)动态sql
持久层框架
6.防止sql注入如何实现
#{} 会被替换成sql中的?调用PreparedStatement set进参数${} 是替换值
字段名不一样,定义resultMap,id标签映射主键并设置column,其他列用result标签
写模糊查询不要写在sql,用#{}传入
7.分页原理:
物理分页:limit offset
逻辑分页
8.数据库索引INNDB的好处
事务,主键索引,外键
自增长列必须是主键,索引的第一个列,而且因为不是表锁要考虑并发增长。
innodb其实不是根据每个记录产生行锁的,根据页加锁,而且用位图。
意向锁。锁定对象分为几个层次,支持行锁、表锁同时存在。
一致性非锁定读:读快照 多版本并发控制:read committed是最新快照,重复读是事务开始时的快照。通过undo完成的。
redo 保证事务的一致性、持久性。undo 保证事务的一致性(回滚)和MVCC多版本并发控制。
不走索引表锁。
myisam 缓冲池之缓存索引文件,不缓存数据。 索引和数据分文件。
脏读
脏页是最终一致性的,数据库实例内存和磁盘异步造成的。脏(数据)读违反了隔离性。
9.mysql日志文件(不是引擎)
server:binlog(逻辑日志,是sql)记录了数据库更改的所有操作。
有3种格式 Statement:sql语句。 row:记录行的更改情况,很占空间,而且对复制的网络开销也增加。mixed。
用于point-in-time恢复、主从复制
只有事务提交时写磁盘一次。
慢查询、查询、错误
数据完整性:记录每个页的更改物理情况
事务进行中,缓存每秒写入一次文件。
内部xa事务
事务提交先写binlog再写reodlog也写入磁盘。
10.mysql为什么可重复读
不可重复读重点在于update和delete,而幻读的重点在于insert。
幻读:虽然可重复读对第一次读到的数据加锁,但是插入还是可以的,就多了一行。
因为binlog的Statement以commit顺序
可重复读会对读取到的数据进行加锁(行锁),保证其他事务无法修改这些已经读过的数据,
MVCC实现可重复读
只有写写之间相互阻塞,其他三种操作都可以并行,这样大幅度提高了InnoDB的并发度
每个数据行会添加两个额外的隐藏列,分别记录这行数据何时被创建以及何时被删除,这里的时间用版本号控制
所有的SELECT操作无需加锁,因为即使所读的数据在下一次读之前被其他事务更新了
行锁会用gap锁锁住一个区间,阻止多个事务插入到同一范围内。是为了解决幻读问题。
一个事务select * from t where a>2 for update;对[2+)加锁,另一个事务插入5失败。
11.mysql主从复制
主节点创建线程发送binlog,读取binlog时会加锁。
mysql在事务提交前,记录binlog。
主库通过发送信号告知从库有新事件。
从节点I/O线程接受binlog,保存在relaylog中继log。
从节点SQL线程读取relaylog,并执行sql。完成数据一致性。
也可以开启放到自身的二进制日志中。
在主库上并发的操作变成串行的。
主节点会为每一个当前连接的从节点建一个binary log dump 进程,而每个从节点都有自己的I/O进程,SQL进程。
复制一个库,先dump一个快照,得到当前快照时对应binlog中的偏移量:日志文件坐标
mysql的两种复制方式:
语句复制:只记录修改数据的查询。更新是串行的,需要很多锁
基于行的复制:实际数据记录在binlog。 但是例如全表更新的操作 行数据让会binlog很大。
12.数据库最左匹配原理
13.jdbc数据库过程
1 | //1加载驱动 |
Spring jdbcTemplate可以将查询结果用RowMapper返回成一个对象list
14.InnoDB的持久化机制
https://juejin.im/post/5b94884af265da0ae74f60d3
buffer pool
包括insert buffer 提高性能
先将这个页面在缓冲池中进行修改,记下相关的【重做日志】,这个页面的修改就算已经完成了。
什么时候真正刷新到磁盘,这个是buffer pool后台刷新线程来完成的
flush链表:在内存中被修改但还没有刷新到磁盘的数据页列表,就是所谓的脏页列表,内存中的数据跟对应的磁盘上的数据不一致
脏页刷新:
redo log
问题:buffer pool和磁盘不一致
记录的是数据页的物理修改,只能恢复到最后一次提交的位置
事务提交时,从buffer pool写入redo log buffer,按时间/事务提交刷新到redo log file。innodb_flush_log_at_trx_commit
有3种设置
1.事务提交fsync
2.事务提交只写page cache
3.提交页不写redo file,等后台刷盘
undo log 实现MVCC!!!
http://mysql.taobao.org/monthly/2015/04/01/
Undo记录中存储的是老版本数据,当一个旧的事务需要读取数据时,为了能读取到老版本的数据,需要顺着undo链找到满足其可见性的记录
每个回滚段又有多个undo log slot
事务开启时,会专门给他指定一个回滚段,以后该事务用到的undo log页,就从该回滚段上分配
提供回滚和多个行版本控制(MVCC)
undo log一般是逻辑日志,根据每行记录进行记录
delete一条记录时,undo log中会记录一条对应的insert记录,反之亦然,当update一条记录时,它记录一条对应【相反】的update记录。
undo log也会产生redo log,因为undo log也要实现持久性保护
当事务提交的时候,innodb不会立即删除undo log,因为后续还可能会用到undo log,如隔离级别为repeatable read时,事务读取的都是开启事务时的最新提交行版本,只要该事务不结束,该行版本就不能删除,即undo log不能删除。
事务提交的时候,会将该事务对应的undo log放入到删除列表中,未来通过purge来删除。
两阶段提交
1.写内存,写redo log,redo log变成prepare (redo log物理日志)
2.server 写binlog (追加写)
3.提交事务,redo log 更新成commit
double write 可靠性
数据库IO最小单位16K,文件系统IO最小单位4K,磁盘IO最小单位512(据说现在也是4K?)
问题:
16K写4次到文件系统(掉电) page 损坏,这种无法通过 redo log恢复
1.内存中的doublewrite buffer 2M,
2.磁盘上共享表空间(ibdata x)中连续的128个页,即2个区(extent),大小也是2M。
刷新脏页流程:
1.内存拷贝:拷贝到内存doublewrite buffer
2.顺序写:从doublewrite buffer(连续存储)到磁盘共享表空间,每次1M
3.然后马上调用fsync函数,同步到磁盘上
预写日志策略WAL,因为只有一个主键并且建了B+树,所以其他辅助索引的插入是离散的,所以,有insert buffer,后台线程优化写操作,转换成连续I/O。
用户表空间的命名规则为:表名.ibd。 通过这种方式,用户不用将所有数据都存放于默认的系统表空间中,但是用户表空只存储该表的数据、索引和插入缓冲BITMAP等信息,其余信息还是存放在默认的表空间中。
ib_logfile0和ib_logfile1的文件,这就是InnoDB的重做日志文件(redo log fiel),它记录了对于InnoDB存储引擎的事务日志。
doublewrite:内存中的2M buffer,磁盘上共享表空间的128个页(2M)
在应用重做日志之前,需要通过副本还原页。页刷新都首先要放入doublewrite。
缓存控制策略:TTL,显式失效/删除,读时失效。
15.分库分表会带来什么问题
跨库join、分布式事务、topK查询
16.外键
多对一关系,多个城市对应于一个省份
城市表中1
2
3
4FOREIGN KEY (`provinceId`) REFERENCES sport_province(`id`)
ON DELETE CASCADE ON UPDATE CASCADE
ON DELETE set null ON UPDATE set null
ON DELETE no action ON UPDATE no action
on delete cascade 删除主表sport_province会一同删除从表sport_city中的数据
on update cascade更新主表sport_province会一同更新从表sport_city中的provinceId
on delete set null 删除主表sport_province,从表sport_city中的数据不会删除,provinceId会置为null。
on update set null更新主表sport_province,从表sport_city中的provinceId会置为null。
on delete no action 不能删除主表。
on update no action 不能更新主表。
17 mysql怎么存储数据 一个节点多大
https://www.cnblogs.com/leefreeman/p/8315844.html
在计算机中磁盘存储数据最小单元是扇区,一个扇区的大小是512字节,而文件系统(例如XFS/EXT4)他的最小单元是块,一个块的大小是4k,而对于我们的InnoDB存储引擎也有自己的最小储存单元——页(Page),一个页的大小是16K。
nnodb的所有数据文件(后缀为ibd的文件),他的大小始终都是16384(16k)的整数倍。
2.网络 web服务器
1.一个端口的连接数太多
Linux中,一个端口能够接受tcp链接数量的理论上限是?无上限
client端的情况下,最大tcp连接数为65535
server端tcp连接4元组中只有remote ip(也就是client ip)和remote port(客户端port)是可变的,因此最大tcp连接为客户端ip数×客户端port数,对IPV4,不考虑ip地址分类等因素,最大tcp连接数约为2的32次方(ip数)×2的16次方(port数),也就是server端单机最大tcp连接数约为2的48次方。
server端,通过增加内存、修改最大文件描述符个数等参数,单机最大并发TCP连接数超过10万 是没问题的
有一个接口一下子快一下子慢
1)用户怎么排查
2)开发者怎么排查
如果是一个数据库接口
2.反爬虫
1)单个IP、session统计 对header user-agent、referer检测
3.7层模型是哪7层
表示层:数据格式变化,加密解密,压缩和恢复 会被放到应用层和会话层
会话层:建立连接,有序传输数据。建立、管理、终止会话。使用校验点,使会话失效时从同步点/校验点恢复通信。(传文件)ADSP ASP
传输层:第一个端到端通信。根据端口分报文到不同的进程。
4.http
如果输入163.com跳转到www.163
301 永久重定向 新地址完全继承就地址,旧网站排名清零
302 临时重定向 新网站不会有排名,google会把302的记录到主域名
303:see other post重定向希望客户端以get请求访问新地址
307:临时重定向 禁止post变成get 针对1.0的307只允许get重定向
206 客户端发送range,服务端有accept-range
响应码
nginx会检查的
405 Not Allowed 必须是GET/POST等指定的方法,header不合法,有下划线等
414 Request URI too Large 请求行太长,超过buffer
400 Bad request 单个header超过单个buffer大小
413 Request Entity Too Large 浏览器发送的Content-Length 超过服务器的包体大小。
502 tomcat没启动 的原因是由于上游服务器的故障,比如停机,进程被杀死,上游服务 reset 了连接,进程僵死等各种原因。在 nginx 的日志中我们能够发现 502 错误的具体原因,分别为:
104: Connection reset by peer,
113: Host is unreachable,
111: Connection refused。
504 上游服务的执行时间超过了 nginx 的等待时间
110: Connection timed out
503 超出限制
QUIC协议已经标准化为Http3协议。基于UDP,但提供了可靠性和流量控制。
可以避免Http2的前序包阻塞
HTTP2
以frame 分帧发送
只建立一个连接 并发发送
服务端推送
重定向的响应头为302,并且必须要有Location响应头;
服务器通过response响应,重定向的url放在response的什么地方?
后端在header里的设置的Location url
重定向可以用于均衡负载
5.nginx
连接池,启动阶段就分配好了,free_connections空闲链表。
网络事件的出发是由内核完成的,所有添加到epoll的事件都会与设备(网卡)驱动程序建立回调关系,相应的时间发生时会回调epoll的callback,把事件放到双向链表中。调用epoll_wait会复制事件到用户空间(内存要自己分配,传一个数组)
其他web服务器有哪些
Nginx采用完全的事件驱动,传统web服务器只有TCP建立、关闭是事件驱动,建立后到关闭之前都不再是事件驱动的,传统web服务器用一个进程or线程作为事件消费者。
Nginx不会用进程/线程作为事件消费者。只有事件收集器、分发器有资格占用进程资源,在分发某个事件时调用消费模块。每个消费者模块都不能阻塞,不然后占用事件分发进程,导致其它事件得不到相应。
10w以上的并发连接
####nginx master和worker怎么通信:
https://www.oschina.net/question/12_13663
Nginx是如何工作的?是如何配置的?
master和worker是如何通信的:
3种消息传递方式:共享内存、套接字、信号
3种同步方式:原子操作,信号量,文件锁
共享内存:由master创建,原子变量统计整个服务器连接状况
套接字对: 协议0,从1写入的可以从0读到:父进程创建一对套接字,父进程关闭sv[1]用sv[0]向子进程发送/接受数据。子进程关掉sv[0]用sv[1]向父进程接收发送数据。每次fork一个子进程都要创建一对。
工作模式:
进程模式:一个master进程管理worker进程,监听连接请求。worker进程处理业务请求,每个worker可以并行处理数千个并发连接和请求。
事件模式:网络、信号、定时器
惊群现象
1)事件驱动、全异步网络I/O 极少进程切换
2)sendfile系统调用 硬盘->网络
3)可靠性:多进程独立
epoll:通过内核与用户空间mmap同一块内存实现的
tomcat nginx apache 区别
Apache和nginx是 Http静态服务器
tomcat 是 Servlet 的容器,处理动态资源。
cookie跨域问题
web1想要拿到web2的cookie KV并且让path变成/web1发ajax,type:get,dataType:jsonp。jsonp利用回调函数,服务端response的outputstream返回document.cookie="k=v;path=/web1"(返回可执行的js代码,回调函数自动执行js)
nginx
nginx的负载均衡策略
1.轮询round robin 按配置文件中的顺序分发
2.最少连接数 活动连接数量最少的服务器
3.IP地址哈希 方便session保存1
2
3
4
5
6
7http {
upstream myapp1 {
//ip_hash, least_conn;
server srv1.example.com;
server srv2.example.com;
server srv3.example.com;
}
4.基于权重的均衡负载
nginx限流是漏桶法
6.正向代理和反向代理的区别
正向代理:隐藏了真实的请求客户端,服务端不知道真实的客户端是谁。需要你主动设置代理服务器ip或者域名进行访问,由设置的服务器ip或者域名去获取访问内容并返回。
反向代理:接收外网请求,转发给内网上游服务器,并将结果返回给外网客户端。
先接受完请求的1G文件,缓存客户端请求,
建立转发,降低上游服务器负载(占用服务器的连接时间会非常短)。
7.nodejs为什么快?
用户态异步实现
单进程,非阻塞异步IO,通过回调高度用户 事件驱动 超过5w
主进程现在只要专心处理一些与I/O无关的逻辑处理
8.为什么是三次握手
三次握手的过程:
https://juejin.im/post/5a0444d45188255ea95b66bc
客户端 端口+SYN=1+序号a SYN_SENT,
服务端 SYN=1,ACK=1,序号b,ack=序号a+1, 客户端ESTABLISHED
客户端 ACK = 1,序号=a+1,ack=b+1,服务端ESTABLISHED
TCP建立连接时就可以确定MSS最大报文段长度。
信道不可靠, 但是通信双发需要就某个问题达成一致. 而要解决这个问题, 三次通信是理论上的最小值。
1)初始化序号 (来解决网络包乱序(reordering)问题),互相通知自己的序号。
2)为了防止已失效的连接请求报文段突然又传送到了服务端,因而产生错误。
如果A发送2个建立链接给B,第一个没丢只是滞留了,如果不第三次握手只要B同意连接就建立了。
如果B以为连接已经建立了,就一直等A。所以需要A再确认。
首次握手隐患:服务器收到ACK 发送SYN-ACK之后没有回执,会重发SYN-ACK。产生SYN flood。
用tcp_syncookies 参数
SYN 洪水攻击:服务端收到客户端SYN后发送SYN和ACK后,客户端不回复,导致服务端大量SYN_RCVD
设置syn ack retry参数加快半连接回收速度。 或者调大syn backlog
9.拥塞控制4种算法
https://www.jianshu.com/p/c9aea5d21152
加法增加乘法减少(AIMD)窗口算法
拥塞控制:慢启动、拥塞避免、快重传、快速恢复4个算法
cwind:发送方维护 拥塞窗口,发送窗口可能小于拥塞窗口 cwind初始值可以设置为10MSS
ssthresh:慢启动门限
(接收缓冲区rwndnet.ipv4.tcp_rmem)
慢启动:cwind 报文数 指数增长 1个最大报文段
拥塞避免:cwind到 慢启动的门限ssthresh线性增长
一旦造成网络拥塞,发生超时重传时 ssthresh为cwind/2, cwind重新【慢启动】
快重传:接收到失序报文 立刻发出重复确认(而不是稍带确认),发送方收到3个重复确认立即重传对方没收到的报文,不用等待重传计时器。
快恢复:当收到3个重复确认(快重传,能收到ack说明没有拥塞)ssthresh为cwind/2,cwind/=2【拥塞避免】
TCP滑动窗口window size 16bit位 可靠性+流量控制+拥塞控制
流量控制:
本质是 动态缓冲区。接收端动态调整窗口大小放在ACK的header中。
window 接收端告诉发送端自己还有多少缓冲区可以接收数据rwnd
option中还有一个窗口扩大因子
10.快重传
当发送方连续收到了3个重复的确认响应的时候,就判断为传输失败,报文丢失,这个时候就利用快重传算法立即进行信息的重传。
拥塞控制主要通过【慢开始,快重传,快恢复和避免拥塞】来实现的。
快恢复 与快重传配合使用,当发送方接收到连续三个重复确认请求,为了避免网络拥塞,执行拥塞避免算法
11.可靠传输的方法 可靠性
如何理解TCP的可靠:
1.send可以发送任意长度,但是数据链路层规定了MTU,TCP会切分报文。
2.每个报文必须ACK否则超时重发
3.TCP接收端重排序失序报文给应用程序
4.当两端速度不一致,防止TCP缓冲区溢出,流量控制。
ARQ自动重传请求协议,确认和重传机制,为提高信道利用率,连续ARQ发送方维护滑动窗口,接收端累计确认。
1.序号 确认应答 超时重传
2.连接管理 数据校验
3.数据合理分片和排序
- UDP:IP数据报大于1500字节,大于MTU.这个时候发送方IP层就需要分片(fragmentation).把数据报分成若干片,使每一片都小于MTU.而接收方IP层则需要进行数据报的重组.这样就会多做许多事情,而更严重的是,由于UDP的特性,当某一片数据传送中丢失时,接收方便无法重组数据报.将导致丢弃整个UDP数据报.
- TCP会按MTU合理分片,接收方会缓存未按序到达的数据,重新排序后再交给应用层。
4、流量控制:当接收方来不及处理发送方的数据,能提示发送方降低发送的速率,防止包丢失。
5、拥塞控制:当网络拥塞时,减少数据的发送。
12.为什么四次分手
1)TCP半关闭。于TCP连接是全双工的,因此每个方向都必须单独进行关闭。
当一方完成它的数据发送任务后就能发送一个FIN来终止这个方向的连接。
收到一个 FIN只意味着这一方向上没有数据流动,一个TCP连接在收到一个FIN后仍能发送数据。首先进行关闭的一方将执行主动关闭,而另一方执行被动关闭。
13.为什么要TIME_WAIT等2MSL 最大报文寿命 Maximum Segment Lifetime
TCP报文段是以IP数据报在网络中传输,IP数据报有TTL字段。
IP数据报对TTL的限制是跳数,不是定时器。
主动关闭方发送的最后一个 ack(fin) ,有可能丢失,这时被动方会重新发fin, 如果这时主动方处于 CLOSED 状态 ,就会响应 rst 而不是 ack。所以主动方要处于 TIME_WAIT 状态,而不能是 CLOSED 。
【rst】是一种关闭连接的方式。
1)可靠地实现TCP全双工连接终止。等最后一个ACK到达。
如果没收到ACK,则被动方重发FIN,再ACK正好是两个MSL。
2)让本连接持续时间内所有的报文都从网络中消失,下个连接中不会出现旧的请求报文。
为什么是2MSL是让某个方向上最多存活MSL被丢弃,另一个方向上的应答最多存活MSL被丢弃。
14.TIME_WAIT 和 CLOSE_WAIT
1)发送FIN变成FIN_WAIT1,然后收到对方ACK+FIN,发完ACK
2)FIN_WAIT1 收到ACK之后到FIN_WAIT2,然后收到FIN,发送ACK。如果最后一个ACK失败,重发FIN但是对方已关闭会得到RST,发送FIN方会报错。
这个状态等2MSL后就CLOSED
作用:让本连接持续时间内所有的报文都从网络中消失,下个连接中不会出现旧的请求报文。
HTTP长连接主动关闭的是server,TIME_WAIT可以修改参数解决。net.ipv4.tcp_tw_recycle = 1可以快速回收TIME-WAIT
CLOSE_WAIT 被动关闭后没有释放连接,一般是代码写的有问题。
TCP连接状态书上一共11种
15.和UDP区别
1)无连接 不可靠 无序
2)广播
3)速度快 报头只有8字节 TCP是【字节流】 20字节(1行32位4字节),数据分段TCP是无边界的,UDP面向【报文】,保留了边界。
16.ping命令原理
https://juejin.im/post/5ba0bb05e51d450e6f2e38a0
输入 ping IP 后敲回车,发包前会发生什么?
如果是域名先要差dns解析ip
1.根据目的IP和路由表决定走哪个【网卡】
2.根据【网卡的子网掩码】地址判断目的IP是否在【子网】内。
同一网段:
3.不在则会通过【arp缓存】查询IP的网卡地址
4.不存在的话会通过[arp广播]询问目的IP的mac地址
5.同一个网段的Ping:A得到mac地址后,把B的MAC地址封装到ICMP包中,向主机B发送一个回显请求
如果A主机192.168.1.1/16,如果B主机192.168.2.1/24
如果Aping B:A用A的子网掩码觉得B是同一网段B能接收到ICMP包,但是B比对自己的子网掩码觉得不是同一网段不发送回应。
不同网段:
3.发送arp找网关MAC
4.把目的MAC是网关,目的IP是主机C的ICMP包
5.路由器去掉原来ICMP的MAC头,MAC源地址改成自己的MAC出地址,目的是查询到C的MAC
6.主机C直接ICMP回显
ICMP回显应答时要输出 序号、TTL、往返时间,目的主机IP地址。
type:回显询问ICMP_ECHO 和回答ICMP_ECHOREPLY
code 总是 0
在ICMP报文的标识符字段设为发送的进程ID。即使多个ping程序也可以识别出返回信息。
序号,用于查看是否有分组 丢失、失序、重复。
输入主机名,ping会用DNS确定主机对应的IP地址。
第一个RTT会比较长,因为会发送一个ARP报文。
发送ICMP请求报文(类型8)一定会从host或者getway返回一个ICMP 响应报文(类型0)
发送一个32字节的测试数据,TTL经过一个路由器就-1. ping 127.0.0.1 TTL是128.
17.输入URL之后经历什么
DNS解析
1)查DNS,浏览器缓存,操作系统先查hosts,查本地DNS缓存,路由器缓存,向DNS服务器发UDP包
2)IP包到网关需要知道网关的MAC地址,用ARP
3)DNS服务器会去查根据名服务器得到注册的域名服务器
TCP建立连接
4)得到IP给浏览器,浏览器,发TCP建立连接
HTTP请求/响应
5)接到重定向到Https,
DNS工作原理
dns名称服务器自高到低分为4个级别:根名称服务器、顶级名称服务器、权威名称服务器和本地域名服务器。
主机向本地域名服务器的查询一般都是采用递归查询。
递归查询返回的查询结果或者是所要查询的IP地址,或者是报错,表示无法查询到所需的IP地址。
1.本地域名服务器向【根域名服务器】的查询的【迭代查询】。
2.【根域名服务器】通常是把自己知道的【顶级域名服务器】的IP地址告诉本地域名服务器,让本地域名服务器再向顶级域名服务器查询。
3.【顶级域名服务器】在收到本地域名服务器的查询请求后,要么给出所要查询的IP地址,要么告诉本地服务器下一步应当向哪一个【二级名称服务器】进行查询。
4.二级域名服务器查询 这个域名 对应的【权威名称服务器】并返回给本地域名服务器。
5.本地域名服务器向权威域名服务器查询并得到ip地址。(或者是返回权威域名找不到就是没有)
如果这个权威名称服务器上配置了指向其它名称服务器的转发器,则权威名称服务器还会在转发器指向的名称服务器上进一步查询。
18.HTTP 长连接怎么实现
HTTP管道是什么,客户端可以同时发出多个HTTP请求,而不用一个个等待响应
在响应到达之前,可以将多条请求放入队列,当第一条请求发往服务器的时候,第二第三条请求也可以开始发送了,在高延时网络条件下,这样做可以降低网络的环回时间,提高性能。
HTTP客户端不应该用管道化的方式发送回产生副作用的请求,比如POST请求。
必须按照与请求相同的顺序回送HTTP响应,因为HTTP报文中是没有序列号的,所以如果收到的响应失序了,就没办法将其与请求匹配起来
管线化是把多个HTTP请求放到一个TCP连接中一一发送,而在发送过程中不需要等待服务器对前一个请求的响应,只不过,客户端还是要按照发送请求的顺序来接收响应,也就是说,如果第一个请求耗费了服务器很多的处理时间,那么后面的请求都要等待第一个处理完,也就出现了线头阻塞。
HTTP2 提供了 Multiplexing 【多路传输】特性,可以在一个 TCP 连接中同时完成多个 HTTP 请求。
那么在 HTTP/1.1 时代,浏览器是如何提高页面加载效率的呢?主要有下面两点:
Chrome 最多允许对同一个 Host 建立六个 TCP 连接。
维持和服务器已经建立的 TCP 连接,在同一连接上顺序处理多个请求。
和服务器建立多个 TCP 连接。
19.http https
HTTP+ 加密 + 认证 + 完整性保护 =HTTPS
总共有3个随机数,客户端随机数,服务端随机数,预主密钥,
对2个随机数和预主密钥生成主密钥用于之后数据加密
https的过程:
- 握手过程
1.客户端client hello发送 随机数+支持的套件
2.服务端server hello返回2个包,1)随机数+选择套件,2)证书(身份认证)
3.握手完成,客户端返回用服务端公钥加密的预主密钥
完成后两边都有预主密钥+2个随机数,用约定的hash算法,生成主密钥进行数据传输
http先和ssl通信,再ssl和tcp通信。
在交换密钥环节使用【公开密钥】加密方式,
之后的建立通信交换报文阶段则使用【共享密钥】加密方式。
对称和非对称 随机码用来? 随机数是用来干嘛的
随机码用服务端的公钥加密,

http 有9种方法
RSA:
两种方式:
1)全密文:用对方公钥加密,对方用私钥解密
2)明文+印章(防抵赖):用自己私钥签名,对方用公钥验签
使用AOP实现
20.网络编程的一般步骤
1应用程序调用listen的时候,内核为这个端口建立 SYN和ACCEPT队列
2客户端connect发送SYN到达服务端后,内核把这个连接放入SYN队列并返回SYN+ACK
3客户端再次ACK内核从SYN队列中取出放入ACCEPT队列
4.调用accept方法时是从accept队列中取出建立好的连接。
如果应用程序不及时accept就会导致两个队列满。Nginx的每个worker负责调用accept方法
21. 糊涂窗口综合征
发送端应用进程产生数据很慢、或者接收端应用进程处理接收缓冲区数据很慢,或者两个情况同时存在;使得通信两端传输的报文段很小。有效载荷可能只有1个字节;而传输开销有40字节(20字节的IP头+20字节的TCP头)。
1.ack捎带合并成一个ack报文
21.Nagel和ACK延迟
Nagle算法关心的是网络拥塞问题,只要所有的ACK回来则发包。
当达到的数据已经达到发送窗口大小的一半或者已经达到报文段的最大长度时,就可以立即发送一个报文段。
CORK算法:提高网络利用率,理想情况下,完全避免发送小包,仅仅发送满包以及不得不发的小包
一个TCP连接上最多只能有一个未被确认的分组,在该分组被确认之前不能够发送其他的分组。
自适应:数据被对端确认的越快,发送端数据发送的也就越快。
ACK延迟 将ACK和数据包一起发送 有定时器
20字节IP首部,20字节TCP
一起用会出现延迟40ms超时后才能回复ACK包
客户端发送了一条报文给服务端,之后等待服务端的确认;而服务器在收到报文之后并不立即返回ack而是等待。等待的原因可以是ack捎带,也可以是认为服务器认为客户端提供的信息不足够重复等待期望更多数据,无论是哪一种情况都势必陷入一个死锁的状态:双方都在等待对方的消息。通常情况超时才能打破这种僵局,但这显然是一种无意义的消耗。
TCP使用另一种传输策略,允许发送方在停止并等待确认前可以连续发送多个分组。
22. restful风格
URL定位资源,用HTTP动词(GET,POST,DELETE,DETC)描述操作。
post 和put的区别
GET 用于信息获取,而且应该是安全的 和 幂等的。
POST 表示可能修改变服务器上的资源的请求。HTTP 协议中规定 POST 提交的数据必须在 body分中。
23 IO模型
异步IO是内核等待内核缓存区数据就绪,然后由内核负责将数据拷贝到用户空间缓冲区,再发送实现完成信号,而同步IO是发送内核缓冲区数据就绪信号,将数据copy到用户缓冲区还是由应用程序进行io系统调用实现。同步IO又包括阻塞IO、非阻塞IO、IO多路复用和信号IO模式。
阻塞和非阻塞:
https://www.jianshu.com/p/dfd940e7fca2
阻塞IO:等待数据(收到一个完整的TCP包)和系统内核拷贝到用户内核都阻塞了。
非阻塞IO:内核数据没准备好直接返回错误,需要轮询。
非阻塞IO需要和IO通知机制一起使用。
I/O通知机制:1) I/O复用函数【向内核注册一组事件】,内核通过I/O复用函数把就绪事件通知给应用程序。 I/O复用函数本身是阻塞的,可以同时监听多个I/O事件。
2)SIGIO信号。
accept()为什么会阻塞?
即使用多线程,serverSocket.accept()询问操作系统的客户端连接accept()还是单线程的,系统级别的【同步】网络I/O模型。
阻塞,非阻塞是程序级别的,同步非同步时操作系统级别的。
多路复用IO模型:操作系统在一个端口上同时接受多个客户端I/O事件。
事件驱动IO。select阻塞轮询所有socket,可以同时处理多个连接,(连接数不高的话不一定比多线程阻塞IO好)优势不在于单个连接处理更快,在于能处理更多的连接。而且单线程执行,事件探测和事件响应在一起。
以上三个都属于同步IO,都会阻塞进程。
select/poll/epoll都需要等待读写时间就绪后读写,异步IO会把数据从内核拷贝到用户。
epoll是根据每个fd上面的callback函数实现的。而且有mmap内核空间和用户空间同处一块内存空间。
如何理解 nio是同步非阻塞
操作系统会创建一个由文件系统管理的socket对象(如下图)。这个socket对象包含了发送缓冲区、接收缓冲区、等待队列等成员。
等待队列是个非常重要的结构,它指向所有需要等待该socket事件的进程。
普通阻塞IO
https://zhuanlan.zhihu.com/p/64138532
Socket的【等待队列】:
程序执行到recv时,【操作系统】会将【进程A】从工作队列移动到该socket的等待队列中(如下图)。由于工作队列只剩下了进程B和C,依据进程调度,cpu会轮流执行这两个进程的程序,不会执行进程A的程序。所以进程A被阻塞,不会往下执行代码,也不会占用cpu资源。
接收:
当socket接收到数据后,【操作系统】将该socket等待队列上的进程重新放回到工作队列,该进程变成运行状态,继续执行代码。也由于socket的接收缓冲区已经有了数据,recv可以返回接收到的数据。
recv阻塞期间,计算机收到了对端传送的数据(步骤①)。
数据经由网卡传送到内存(步骤②),
然后网卡通过【中断信号】通知cpu有数据到达,cpu执行中断程序(步骤③)。
此处的中断程序主要有两项功能,先将网络数据写入到对应socket的【接收缓冲区】里面(步骤④),再唤醒进程A(步骤⑤),重新将进程A放入【工作队列】中。
阻塞和非阻塞:
阻塞IO:等待数据(收到一个完整的TCP包)和系统内核拷贝到用户内核都阻塞了。
非阻塞IO:内核数据没准备好直接返回错误,需要轮询,在单线程内就可以完成所有连接接收工作。
IO多路复用模型(事件驱动模型):可以一次性检测多个连接是否活跃,通知用户进程。不一定比多线程阻塞IO好,但是单线程能处理更多的连接,cpu消耗少。用户进程还是被select函数阻塞。
信号驱动IO的特点是IO可用的时候程序被中断,然后由中断函数处理IO事件。
select
进程A管理所有要监听的scoket。
操作系统把进程A分别加入这三个socket的等待队列中。
进程A被唤醒后,它知道至少有一个socket接收了数据。程序只需【遍历一遍socket列表】,就可以得到就绪的socket。
唤起进程,就是将进程从【所有】的等待队列中移除,加入到工作队列里面。
用户进程调用select,进程阻塞,当任何一个socket准备好,调用read完成内核到用户的拷贝。
问题:
1.每次调用select都需要将进程加入到【所有】监视socket的【等待队列】,每次唤醒都需要从【每个队列】中移除。每次都要将整个fds列表传递给内核。默认只能监视1024个。
2.不知道哪个socket接到数据,要遍历。
低效的原因:
将“维护等待队列”和“阻塞进程”两个步骤合二为一。
事件检测和事件响应在一起,如果事件响应太大,下一个事件将不能执行。
epoll
先用epoll_ctl维护等待队列,再调用epoll_wait阻塞进程。
用红黑树管理监视的socket,用双向链表实现就绪队列。
1.epoll对象eventpoll,维护了一个就绪列表rdlist。
2.内核会将eventpoll添加到这三个socket的等待队列中。
3.中断程序操作epoll对象而不是进程。回调函数,将收到的socket加入就绪队列
4.当程序执行到epoll_wait时,如果rdlist已经引用了socket,那么epoll_wait直接返回,如果rdlist为空,阻塞进程。
epoll 和 select的区别
select是一个系统调用,而epoll是个模块,由三个系统调用组成
http://armsword.com/2014/03/07/linux-io-multiplexing/
首先,其不用每次调用都向内核拷贝事件描述信息,在第一次调用后,事件信息就会与对应的epoll描述符关联起来。另外epoll不是通过轮询,而是通过在等待的描述符上注册回调函数,当事件发生时,回调函数负责把发生的事件存储在就绪事件链表中,最后写到用户空间。
如何理解 nio是同步非阻塞
由一个专门的线程(Selector)来处理所有的IO事件,并负责分发。
事件驱动机制:事件到的时候触发,而不是同步的去监视事件。
线程通讯:线程之间通过 wait,notify 等方式通讯。保证每次上下文切换都是有意义的。减少无谓的线程切换。
边缘触发ET和水平触发LT
边缘触发ET:只能处理非阻塞套接字,如果没有处理完这个事件对应的套接字缓冲区,这个套接字没有新事件,无法再次从epoll_wait调用中再次获取这个事件。 如果没有彻底将缓冲区数据处理完,会导致缓冲区中的用户请求得不到相应。
水平触发LT:可以处理非阻塞和阻塞的套接字,一个事件的缓冲区还有数据,就可以epoll_wait获取这个事件。
https://www.jianshu.com/p/7835726dc78b
ET边缘触发:即使有数据可读,但是没有新的IO活动到来,epoll也不会立即返回.
epoll默认是LT水平触发
Level信号只需要处于水平,就一直会触发;而edge则是指信号为上升沿或者下降沿时触发
Epoll事件分派接口可以表现为边沿前触发 (ET)和 水平触发(LT).这两个机制之间的区别可以描述如下。
ET模式只有在被监控文件描述符发生变化时才递交事件
同步和异步
是否等待 IO操作完成后,控制权才返回给用户进程。
读操作:1)等待数据 2)从内核拷贝到进程
事件处理模式
Reactor模式实现同步I/O,处理I/O操作的依旧是产生I/O的程序
https://www.nowcoder.com/ta/review-c/review?page=54
reactor模型要求主线程只负责监听文件描述上是否有事件发生,有的话就立即将该事件通知工作线程,除此之外,主线程不做任何其他实质性的工作,读写数据、接受新的连接以及处理客户请求均在工作线程中完成。
异步I/O 订阅-通知:立即返回,内核完成数据准备+拷贝数据之后发送给用户进程一个信号。
Proactor实现异步I/O,产生I/O调用的用户进程不会等待I/O发生,具体I/O操作由操作系统完成。
异步I/O需要操作系统支持,Linux异步I/O为AIO,Windows为IOCP。
24 Reactor模式!!!
Java提供了2种异步编程模型
1.回调 事件的Listener
2.Future
观察者模式 发布订阅模式 事件通知机制 Promise模式
一对多关系。
网页事件绑定、UI事件监听机制全都是观察者模式。
好处
25 端口复用 SO_REUSEADDR
1 | s = socket(AF_INET,SOCK_STREAM,0); |
3.操作系统
1.进程状态
R 运行
S 睡眠(可中断)
D IO等待睡眠状态(不可中断)
T 暂停状态
Z 僵尸态
2.进程间通信
套接字,管道,命名管道、邮件槽、远程过程调用、消息队列,共享内存,信号量,信号。
使用场景:进程间数据共享:共享内存 进程间数据交换:socket、消息队列。
信号:异步的通知机制,用来提醒进程一个事件已经发生
信号是在软件层次上对中断机制的一种模拟。
trap -ltrap "" INT 表明忽略SIGINT信号,按Ctrl+C也不能使脚本退出
https://github.com/xuelangZF/CS_Offer/blob/master/Linux_OS/IPC.md
管道只能两个进程
消息队列能多个进程
管道 【随进程持续】:
管道的本质是内核维护了一块缓冲区与管道文件相关联。
1)单向 半双工:把一个程序的输出直接连接到另一个程序的输入
2)除非读端已经存在,否则写端的打开管道操作会一直阻塞
3)只能父子进程、兄弟进程
4)无格式字节流,需要事先约定数据格式。
匿名管道:内存文件描述符(内核)。
1)pipe(2)系统调用时,这个函数会让系统构建一个匿名管道
2)这样在进程中就打开了两个新的,打开的文件描述符:父进程关闭管道读端,子进程关闭管道写端。
3)一般再fork一个子进程,然后通过管道实现父子进程间的通信。
4)通过只在【内存】(内核)中的文件描述符fd[0]表示读 fd[1]表示写。(父子进程分别关闭一端组合成父进程->子进程/子进程->父进程的管道)
命名管道FIFO文件:提供一个路径名与之关联,以FIFO文件形式存在于【文件系统】
mkfifo()
可以通过文件的路径来识别管道,从而让没有亲缘关系的进程之间建立连接。
1)读管道程序 mkfifo创建管道文件,死循环read
2)写程序 打开管道文件写。
借助了文件系统的file结构和VFS的索引节点inode。过将两个file 结构指向同一个临时的VFS 索引节点,而这个VFS引节点又指向一个物理页面
管道和命名管道都是随进程持续的,而消息队列还有后面的信号量、共享内存都是随内核持续的
消息队列(链表) msgget(同一台机器) 系统内核: (一种逐渐被淘汰的方式)
msgid = msgget((key_t)1234, 0666 | IPC_CREAT);msgget()msgrcv()
1)异步:消息队列本身是【异步】的,消息队列独立于进程存在。它允许接收者在消息发送很长时间后再取回消息
2)消息必须以long int 开头 , 接收程序可以通过消息类型有选择地接收数据。
3)可以同时通过发送消息,避免命名管道的同步和阻塞问题,不需要由进程自己来提供同步方法。
4)轮询:收者必须轮询消息队列,才能收到最近的消息。
5)优先级
6)与管道相比,消息队列提供了有格式的数据 【读写双方都需要msgget建立消息队列】
7)和信号相比,消息队列能够传递更多的信息
共享内存shmget 最快但是无法解决同步
1)shmget创建一个 结构体大小的共享内存,有权限
2)shmat 映射到进程的地址空间。
3)读写的时候要用written标志防止两个进程同时读写 而且要把written变成原子操作
4)shmdt可以分离共享内存1
2
3
4struct shared_use_st{
int written;
char text[2048];
};
同一个Linux机器的两个进程访问同一块共享内存,他们访问共享内存中的同一个对象的时候,指针相同吗?
可能相同也可能不同
信号量semget 有权限
不是线程同步的posix信号量,是SYSTEM V信号量
信号量能解决 共享内存同步问题
3.进程调度方式 CFS 调度周期 计算运行时间vruntime
Linux CFS 完全公平调度器:
首先分实时进程和普通进程
实时进程:1)FIFO运行直到有更高优先级2)RR时间片,优先级高的先运行。
就绪实时进程抢占非实时进程。
普通进程:曾今使用CPU最少的优先
1.设定一个【调度周期】(sched_latency_ns),目标是让每个进程在这个周期内至少有机会运行一次。每个进程等待CPU的时间最长不超过这个调度周期。
2.进程的数量,大家平分这个调度周期内的CPU使用权,由于进程的优先级即nice值不同,分割调度周期的时候要加权;
3.每个进程的【累计运行时间】保存在自己的vruntime字段里,哪个进程的vruntime最小就获得本轮运行的权利。
细节
问题1:新进程
fork之后的子进程优先于父进程
每个CPU的运行队列cfs_rq都维护一个min_vruntime字段,记录该运行队列中所有进程的vruntime最小值,防止一直fork获得时间片,新进程一般要设置比min_vruntime大。
问题2:休眠进程
唤醒抢占特性
被唤醒时当新进程重新设置vruntime
问题3:频繁抢占
CFS设定了进程占用CPU最小时间,如果进程太多,调度周期会根据最小时间x进程数
问题4:进程切换CPU
为保持相对公平,vruntime要减去当前CPU的min,在加到CPU2的min上
红黑树而不用最小堆
每个核用红黑树选区vruntime最小的进程
进程调度有很多遍历操作,需要完全排序
红黑树插入最多两次旋转,删除最多3次旋转,染色Logn
进程的上下文切换:切换会保存寄存器、栈,需要用户态切换到内核态
4.内存分页与swap
内存屏障 指令乱序 分支预测 CPU亲和性affinity Netfilter和iptables
5. 死锁
原因:资源不足、进程运行推进顺序不合理、资源分配不当、占用资源的程序崩溃
5.1死锁条件
死锁是指两个或两个以上的进程在执行过程中,因争夺资源而造成的一种互相等待的现象,若无外力作用,它们都将无法推进下去。
死锁的发生必须满足以下四个条件:
- 互斥条件:一个资源每次只能被一个进程使用。
- 请求与保持条件:一个进程因请求资源而阻塞时,对已获得的资源保持不放。
- 不剥夺条件:进程已获得的资源,在末使用完之前,不能强行剥夺。
- 循环等待条件:若干进程之间形成一种头尾相接的循环等待资源关系。
5.2死锁处理策略
1)预防死锁 前面4个条件 2)避免死锁 银行家算法 3)死锁检测再解除
互斥条件:SPOOLing 技术,将打印机变成共享设备,加一个队列。
不剥夺条件:得不到就放弃自己的 或者直接抢
请求和保持条件:静态分配(进程运行前一次性分配全部资源)
循环等待条件:顺序资源分配法 对资源加编号 同类资源一次性分配完
6.段页式管理每一次数据要访问几次内存
系统必须为每个作业或进程建立一张段表以管理内存分配与释放、缺段处理、存储保护相地址变换等。另外,由于一个段又被划分成了若干页,每个段又必须建立一张页表以把段中的虚页变换成内存中的实际页面。
第一次是由【段表地址寄存器】得段表始址后访问【段表】,由此取出对应段的【页表】在【内存】中的地址。
第二次则是访问【页表】得到所要访问的物理地址。
第三次才能访问真正需要访问的【物理单元】。
4.java基础
1.Java 类加载的过程
将编译好的类文件中的字节码文件加载到内存中,放在方法区内并创建Class对象。
双亲委派原则:每个加载器对应不同的加载目录。先检查这个类是否加载过,不然调用父加载器的loadClass,如果父加载器(在搜索范围内没这个类)抛出异常,调用自己的findClass()。
好处:避免类的重复加载,避免核心API被纂改。无论哪个类加载器要加载。都委派给启动类加载器,类随类加载器有层级关系,Objet都是同一个类。
类加载的过程包括了【加载、链接(验证、准备、解析)、初始化】五个阶段
加载:1)获取二进制字节流2)静态存储结构(字面量和符号引用)放到【运行时数据区】。堆中生成3)Class对象,作为方法区类数据的访问入口,hotspot放在方法区里。
验证:文件格式、元数据、字节码(数据流、控制流)、符号引用 验证
准备:分配内存,设初始值
解析:符号引用->直接引用
初始化:如果父类没有初始化,会先初始化父类
解析可能在初始化之后。
初始化阶段有且只有5种主动加载的情况:
1)new,静态方法、静态字段(被final放到常量池的静态字段除外)
2)反射Class.forName
3)作为父类,子类被初始化
4)调用main
5)MethodHandle??
每个类都会使用 当前类加载器(自己的类加载器)加载依赖的其它对象
https://www.jianshu.com/p/05ec26e25627
线程类加载器:继承父线程的上下文类加载器,运行初始线程上下文类加载器是Applicaton
mysql的Connection接口是JDK内置的rt.jar,由bootstrap类加载器加载的,但是厂商的实现是applicaton类加载器加载的,双亲委托模型
类加载器如何回收?
2.垃圾回收机制
Minor GC执行时间不到50ms;
Minor GC执行不频繁,约10秒一次;
Full GC执行时间不到1s;
Full GC执行频率不算频繁,不低于10分钟1次;
新生代有什么算法
Minor GC Eden清空。
Survivor为什么要有2个:
如果只有一个Survivor,Survivor需要清理的对象就只能标记清除了。
每次 Minor GC,会将之前 Eden 区和 From 区中的存活对象复制到 To 区域。第二次 Minor GC 时,From 与 To 职责兑换,这时候会将 Eden 区和 To 区中的存活对象再复制到 From 区域,以此反复。
永远有一个 Survivor space 是空的,另一个非空的 Survivor space 是无碎片的
4大算法:
1.标记清除 存活多高效
2.标记整理 GC的停顿时间长,无碎片
3.复制算法 浪费空间
4.分代回收
引用计数,复制,标记清除,标记压缩
7个垃圾收集器
串行收集器:对应young和old两个收集器
并行收集器:对应young和old两个收集器 【吞吐量】优先 JVM的默认垃圾回收器 多线程进行垃圾回收
并发收集器:CMS、G1 停顿时间优先
G1和CMS的最大区别:
G1是新生代老年代都是用的算法,CMS只能和parnew一起用,
G1是标记整理(region之间的复制)cms是标记清除有碎片,
G1有停顿时间预测模型。
CMS7个步骤 标记清除算法, -XX:CMSFullGCsBeforeCompaction=n 压缩
1.初始标记STW root和年轻代到老年代的引用
2.并发标记
3.重新标记STW 包括young和old 可以先执行young gc-XX:+CMSScavengeBeforeRemark
4.并发清理
5.并发重置
串行收集器适合单核CPU或者非常小堆。ES默认使用CMS收集器
HBase年轻代 并行回收ParallelGC 老年代CMS并发收集器
Socket缓冲区:每个Socket连接都有Receive和Send两个缓冲区,分别占用大约37KB和25KB的内存。
G1算法
什么时候对象会被回收?如果互相引用
http://blog.jobbole.com/109170/
强引用=null
引用计数算法 无法解决互相引用的情况。
所以用的是 可达性分析算法:判断对象的引用链是否可达。
如果循环引用,没有人指向这个环也会被回收。
从GC root(栈中的本地变量表中的对象、类(方法区)常量、静态属性引用的对象、活跃线程)
JIT编译时会在安全点记录下很多OopMap(一个对象内 偏移量:类型数据)压缩在内存中。
GC的时候扫描对应偏移量
类回收:
1.ClassLoader已经被回收,2.Class对象没有引用,3.所有实例被回收。
资源管理,如果数据库连接对象被收回,但是没有调用close,数据库连接的资源不会释放,数据库连接就少一个了,要放在try()里。
gcroot是什么
GC会收集那些不是GC roots且没有被GC roots引用的对象。
Class - 由系统类加载器(system class loader)加载的对象,这些类是不能够被回收的,他们可以以静态字段的方式保存持有其它对象。我们需要注意的一点就是,通过用户自定义的类加载器加载的类,除非相应的Java.lang.Class实例以其它的某种(或多种)方式成为roots,否则它们并不是roots,.
Thread - 活着的线程
Stack Local - Java方法的local变量或参数
JNI Local - JNI方法的local变量或参数
JNI Global - 全局JNI引用
Monitor Used - 用于同步的监控对象
Held by JVM - 用于JVM特殊目的由GC保留的对象,但实际上这个与JVM的实现是有关的。可能已知的一些类型是:系统类加载器、一些JVM知道的重要的异常类、一些用于处理异常的预分配对象以及一些自定义的类加载器等。
full GC
1)System.gc()方法的调用
2)老年代空间不足
3)Minor GC后超过老年代可用空间
4)分配很大的对象没有足够的空间
5)CMS promotion failed:年轻代gc survivor放不下,老年代也放不在
full GC:当准备要触发一次young GC时,如果发现统计数据说之前young GC的平均晋升大小比目前old gen剩余的空间大,则不会触发young GC而是转为触发full GC(因为HotSpot VM的GC里,除了CMS的concurrent collection之外,其它能收集old gen的GC都会同时收集整个GC堆,包括young gen,所以不需要事先触发一次单独的young GC);或者,如果有perm gen的话,要在perm gen分配空间但已经没有足够空间时,也要触发一次full GC;或者System.gc()、heap dump带GC,默认也是触发full GC。
3.Object有哪些方法
还有getClass() 和finalize
wait 方法必须在synchronized内用
4.JVM分哪几个区 - JVM内存模型
虚拟机运行时数据区、类加载器、执行引擎、本地方法库
线程独占:
1)程序计数器-多线程轮流切换并分配处理器执行时间,多线程切换后恢复到正确的执行位置。
2)虚拟机栈
3)本地方法栈
线程共享:
堆、方法区(永久代、metaspace)
介绍JVM堆和栈,有什么用
虚拟机栈:生命周期与线程相同。Java 方法执行的内存模型,局部变量表、返回地址、操作数栈、动态链接(?)
5.Java内存分配策略
Java 程序运行时的内存分配策略有三种,分别是静态分配,栈式分配,和堆式分配,对应的,三种存储策略使用的内存空间主要分别是方法区(静态储存区)、栈区和堆区
方法区(静态储存区):静态域都存在于这个区域中;图中我们还可以看到该区域中存在一个“常量池”的区域,这个区域主要存放常量,包括我们在代码中通过final声明的字段(不包括局部的final)和各种编译器生成的常量。这里说一下,我们知道静态实例是在类加载时初始化,而这里的常量池是在编译期就分配好的。
下列Java代码中的变量a、b、c分别在内存的____存储区存放。1
2
3
4
5
6
7class A {
private String a = “aa”;
public boolean methodB() {
String b = “bb”;
final String c = “cc”;
}
}
堆区、栈区、栈区
a是成员变量/实例变量的引用,这个引用是储存在堆区中的;“aa”是未经 new 的常量,在方法区的常量区中。
b 为局部变量的引用,在栈区;“bb”为未经 new 的常量,在常量区。
Java对象的内存分配主要是指在堆上分配(也有经过JIT编译后被拆散为标量类型并间接地在栈上分配的情况),对象主要分配在新生代的Eden区上,如果启动了本地线程分配缓冲,则将按线程优先在TLAB(Thread Local Allocation Buffer)上分配。
怎么把对象分配到老年代上
6.泛型的好处
泛型:向不同对象发送同一个消息,不同的对象在接收到时会产生不同的行为(即方法);也就是说,每个对象可以用自己的方式去响应共同的消息。消息就是调用函数,不同的行为是指不同的实现(执行不同的函数)。
用同一个调用形式,既能调用派生类又能调用基类的同名函数。
7.方法的重载和重写都是实现多态的方式,
区别在于前者实现的是编译时的多态性,而后者实现的是运行时的多态性。
- 为什么不能根据返回类型来区分重载?
因为调用时不能指定类型信息,编译器不知道你要调用哪个函数。
虚函数是实现多态 “动态编联”的基础,C++中如果用基类的指针来析构子类对象,基类的析构要加virtual,不然不会调用子类的析构,会内存泄漏。
8.虚拟机如何实现多态
当程序运行需要某个类时,类加载器会将相应的class文件载入到JVM中,并在方法区建立该类的类型信息(包括方法代码,类变量、成员变量、方法表)
方法表是实现动态调用的核心。为了优化对象调用方法的速度,方法区的类型信息会增加一个指针,该指针指向记录该类方法的方法表,方法表中的每一个项都是对应方法的指针。
这些方法中包括从父类继承的所有方法以及自身重写(override)的方法。
解析调用:方法是一个常量池中的符号引用。静态方法(类型绑定),私有方法(外部不可访问)在类加载【解析】阶段把所有符号引用变为可确定的直接引用。
分派调用:
重载:静态分派,编译期间依赖静态类型(左边)定位方法版本。应用:重载。变异期间选择重载版本。
静态多分派,动态单分派。
重写:动态分派,虚拟机根据实际类型分派,invokevirtual指令 调用虚方法。运行期在操作数栈顶找到对象的实际类型(运行时确定方法的接收者类型),将常量池中的方法符号引用解析到不同的直接引用上。
每个类在方法区中有 虚方法表,子类重写方法,子类放发表里换替换为子类实现的版本地址。
相同签名的方法,在父类、子类需方发表都应有一样的序号。
链接阶段进行初始化方法表(?)
9.除了基本类型还有那些类能表示数字
包装类,高精度BigDecimal,原子类
Atomic内部用native方法,使用了硬件支持的CAS
1.8新加的原子类LongAdder 分离热点
把value变成一个数组,变成hash计数,计数结果就是累加结果。
10. java修饰符
访问修饰符:
可以对 类、变量、方法、构造方法访问控制
private不能修饰外部类
protected不能修饰外部类
protected修饰的变量子类在其他包中也可以访问,但是default情况下的变量子类只能在同级包中才可以访问。
非访问修饰符:static final abstract synchronized volatile
protected【同包内的类】 和所有子类可见!!!
11.线程/进程调度方式
适用于批处理系统:吞吐量、周转时间、CPU利用率 再考虑公平
1.FCFS 先来先服务,对长作业有利,短作业不利
2.短作业优先算法,抢占式的:3.最短剩余时间优先
在所有进程可以同时运行时,短作业优先算法可以得到最短的平均周转时间,会产生长任务【饥饿】
4.高响应比调度算法(非抢占)折中 等待时间和短作业有更高响应比
交互式系统:公平、响应
1.时间片轮转调度,优先级调度,多级反馈队列调度,高响应比优先调度(有改良版,IO进程用不完时间片所以给IO进程设置一个辅助队列,优先执行辅助队列而不是就绪队列。
2.优先级调度(动态/静态优先级)IO高于CPU进程。不公平,优先级低的会饥饿。抢占式会 优先级反转(低优先级的占用了高优先级的资源,中优先级抢占后都阻塞)
3.多级反馈队列调度算法(抢占式)多个就绪队列,各队列按时间片轮转调度 对IO进程有利,CPU进程会饥饿
4.最短进程优先
vmstat 看cs 是context switch 线程上下文切换次数
左边r和b是cpu运行队列和阻塞队列的长度(运行队列中轻量级线程的实际数量)
pidstat -w cswch/s 主动上下文修换 nvcswch/s 被动上下文切换
上下文切换还包括系统调用。
us 用户CPU时间
sy 系统CPU时间
协同式线程调度(协程,每个线程执行时间由线程本身控制)
java:抢占式线程调度(操作系统分配时间)
java线程是映射到操作系统原生线程上的。
12.String StringBuilder StringBuffer
String 存在JVM哪里
1)一旦有一个用引号的字符串就会放到字符串常量池。
2)拼接创建的只在堆里。
3)堆里面创建新的字符串,用intern可以放【引用】到常量池(jdk1.7之前只只能放一个副本放到常量池)
方法区,方法区是JVM的一种规范。元空间MetaSpace和永久代PermGen都是方法区的实现。
原来在永久代里的字符串常量池移到了堆中。而且元空间替代了永久代。
本来永久代使用的是JVM内存,而元空间使用的是本地内存,字符串常量不会有性能问题(intern)和内存溢出。
13 !!!线程安全的单例模式
单元素枚举类是实现Singleton的最佳方法1
2
3
4
5
6
7
8
9
10
11public enum Singleton{
//定义1个枚举的元素,即为单例类的1个实例
INSTANCE;
// 隐藏了1个空的、私有的 构造方法
// private Singleton () {}
}
// 获取单例的方式:
Singleton singleton = Singleton.INSTANCE;
【初始化占位类模式】
如果是静态初始化对象不需要显示同步。
静态初始化:JVM在类初始化阶段执行,在类加载后并在线程执行前。JVM会获取锁确保这个类已经被加载。任何一个线程调用getInstance的时候会使静态内部类被加载和初始化。1
2
3
4
5
6
7
8
9public class Singleton {
private static class SingletonHolder {
private static final Singleton INSTANCE = new Singleton();
}
private Singleton (){}
public static final Singleton getInstance() {
return SingletonHolder.INSTANCE;
}
}
用反射强行调用私有构造函数可以创建多个实例。防止序列化:重写私有的readReslove() 当反序列化readObject()的时候会直接调用readReslove替换原本的返回值。
双重检查锁已经被广泛地废弃了!
懒加载 (根本没必要)
如果这个类有多个静态变量,还是应该用懒加载。
不然类只在主动调用的时候加载,其实已经是懒加载了。
懒加载 推迟高开销的对象初始化操作。
同步 double checked locking
只希望在第一次创建 实例的时候进行同步
【创建对象分为3个步骤】:
1)分配内存
2)初始化对象
3)obj指向内存地址
关键:(2)、(3)会被重排序(因为理论上单线程不会有错,而且能提高性能),导致obj不未空,但还没初始化,所以volatile禁止重排序。
如果两个操作之间没有happens-before则JVM可以重排序。
Volatile变量规则。对一个volatile修饰的变量,对他的写操作先行发生于读操作。
特别对于有final字段的对象,构造函数完成的时候才完成final的写入。
初始化安全:防止对对象的初始引用被重排序到构造过程之前。
1 | public class LazySingle(){ |
“Monitor”是BLOCKED线程正在等待获取对象上的锁的状态
方法2:静态内部类
14.java线程栈大小
https://www.zhihu.com/question/27844575
Java 中每开启一个线程需要耗用 1MB 的 JVM 内存空间用于作为线程栈
linux的线程栈大小可以使用ulimit -s内核线程栈的默认大小为8M
15.clone和hashCode
16 class文件有什么
https://juejin.im/post/5c0932cee51d45090a1da07e#heading-1
一个class文件对应一个ClassFile结构
21 内存溢出OOM和内存泄漏memory leak
https://www.jianshu.com/p/54b5da7c6816jstat
22 四种引用类型
强引用,软引用,弱引用,虚引用
软引用:内存不够二次回收
弱引用:回收
弱引用应用:优惠券 WeakHashMap<Coupan, <List<WeakReference <User>>>
weakCoupanHM.put(coupan1,weakUserList);
当某个优惠券(假设对应于coupan2对象)失效时,我们可以从coupanList里去除该对象,coupan2上就没有强引用了,只有weakCoupanHM对该对象还有个弱引用,这样coupan2对象能在下次垃圾回收时被回收,从而weakCoupanHM里就看不到了。
当某个用户(假设user1)注销账号时,它会被从List
虚引用:要和引用队列一起使用,用于跟踪垃圾回收的过程
23 Java线程状态
6种
New, Runnable, Timed Waiting, Waiting,Blocked,Terminated
创建线程 new状态
调用start方法后j进入Runnable状态,不能马上运行,要先进入就绪状态等待线程调度(Ready),获取到CPU后到Running状态
如果运行中获取锁失败Blocked状态,获取到后再变成就绪状态
调用Thread.join 或者LockSupport.park方法会进入Waiting可以通过notify或者unpark回到就绪状态。
所以我们把”新建(NEW)”和”终止(TERMINATED)”两种状态去掉,那么Java定义的线程状态还有4种:1. RUNNABLE2. BLOCKED3. WAITING4. TIMED_WAITING这四种状态怎么对应到”就绪”、”阻塞”、”运行”这三种状态里呢:1. RUNNABLE,对应”就绪”和”运行”两种状态,也就是说处于就绪和运行状态的线程在java.lang.Thread中都表现为”RUNNABLE”2. BLOCKED,对应”阻塞”状态,此线程需要获得某个锁才能继续执行,而这个锁目前被其他线程持有,所以进入了被动的等待状态,直到抢到了那个锁,才会再次进入”就绪”状态3. WAITING,对应”阻塞”状态,代表此线程正处于无限期的主动等待中,直到有人唤醒它,它才会再次进入就绪状态4. TIMED_WAITING,对应”阻塞”状态,代表此线程正处于有限期的主动等待中,要么有人唤醒它,要么等待够了一定时间之后,才会再次进入就绪状态
24 运行时找不到方法、类
25 GC多久一次 一次多久
如何查看GC情况jstat jconsole
###
5.分布式
使用过zookpeeper吗
1.使用场景 2.解决的问题 3.特点 4.和其他同类型的框架的比较
全局唯一id
mysql实现1
2
3
4
5
6
7
8
9
10
11
12create table `tic`(
`id` bigint(20) unsigned not null auto_increment,
`stub` char(1) not null default '',
primary key (`id`),
unique key `stub` (`stub`)
)engine = myisam;
start transaction;
replace into tic(stub) values('a');
select last_insert_id();
commit;
1.zookeeper的应用场景
分布式协调 节点注册监听
分布式锁
2.XA事务 分布式事务
事务管理器(Mysql客户端)和资源管理器(Mysql数据库)之间用两阶段提交,等所有参与全局事务的都能提交再提交
用JAVA JTA API
JTA事务是什么???
6.数据结构
1.二叉平衡树的应用 红黑树原理
首先是二叉搜索树(中序有序),防止退化成链表。 默认添加的是红色,默认和其他节点合并。
算法4:红黑树等价于2-3树。2-3树是绝对平衡的树,不会插入一个空节点,而是会合并到应该插入的节点上,如果有3个并排,分裂,提升中间的合并到上一层。
关键性质:红黑树确保没有一条从根到叶子的路径会比其他从根到叶子的路径长出两倍
1)根、叶子节点(空节点)、红色节点的两个儿子都是黑色
2)任一节点到其每个叶子节点的所有简单路径 包含相同数目的黑色节点
AVL树是严格的平衡二叉树
如果应用场景中对插入删除不频繁,只是对查找要求较高,那么AVL还是较优于红黑树。
windows对进程地址空间的管理用到了AVL树
2.排序 希尔排序复杂度
当步长为1时,算法变为普通插入排序
已知最好n(log^2)n
2.堆排序
是选择排序的改进,有O(N)得到堆后,每次选min
3.最小生成树的两种算法
Prim算法,标记已选点,选标记点可达的最近点标记,直到标记完所有点。
贪心选择与当前顶点集合中距离最短的顶点。
把点划分为3类:不可达(不可选),可选,已选
维护一个数组:dis,作用为已用点到未用点的最短距离。
证明:对于任意一个顶点v,连接到该顶点的所有边中的一条最短边(v, vj)必然属于最小生成树(即任意一个属于最小生成树的连通子图,从外部连接到该连通子图的所有边中的一条最短边必然属于最小生成树)
复杂度:O(n^2) n为图中顶点数。适合稠密图。邻接矩阵O(v^2) 邻接表O(elog2v)
Kruskal算法,存在相同权值的边。O(mlogm) m为边树,与顶点数无关
扩展边,每次贪心选择剩余边中最小权重的边。
从权值最小的边开始遍历,直到图的点全部在一个连通分量中。
复杂度:
4.Hash碰撞的方法
1)开放地址法(Nginx的散列表??) 开放地址法分: 线性探测法(会聚集)、平方探测、双散列
2)链地址法
不成功平均查找长度,要按照冲突解决方法查找到当前位置为空位置。最后/散列函数的mod(hash函数的分类个数)
7.框架
1.Spring容器初始化过程
分为容器启动阶段、Bean实例化阶段
1.容器启动阶段:读取解析配置文件,保存成BeanDefinition并注册。
ApplicationContext是实例化所有bean,而BeanFactory是延迟初始化。
2.Bean实例化阶段:根据BeanDefinition实例化对象,并注入依赖。
1.bean工厂后置处理器在容器实例化bean之前:用处:占位符处理器处理el表达式
2.IOC和DI的区别
控制反转
IOC是将创建对象的工作交给Spring容器,对象是被动的被Spring容器创建,即为“反转”,“控制”即为Spring容器控制对象的创建
DI 依赖注入
DI可以说是IOC的一种具体实现
Spring创建对象的过程中,将对象依赖的属性注入到对象中,即创建A对象时将其依赖的B对象也一并创建并注入到A对象中
依赖注入的方式:
属性注入:通过setter方法注入
构造函数注入
工厂方法注入
3.Springboot的启动流程
4.SpringMVC工作原理
1)servlet一共三个层次
HttpServletBean:直接继承java的HttpServlet,将Servlet中的配置参数设置到相应的属性。
FrameworkServlet:初始化WebApplicationContext 抽象类静态方法 将不同类型请求合并到一个方法统一处理。还发布了一个事件。
DispatcherServlet:初始化9大组件
doService方法保存redirect转发的参数和include的request快照。
调用的doDispatch方法4步
1)根据request找到handler(@RequestMapping)
2)用mapper根据handler找到handlerAdapter 处理不同参数(不只是request和response)
3)handlerAdapter处理,先执行拦截器。Last-Modified
4)processDispatchResult处理View
5. 如何注入私有成员变量
https://blog.csdn.net/u012280292/article/details/80416691
8.并发
1.协程 轻量化 用户态调度 切换代价比线程上下文切换低
非抢占式用户态线程
与进程和线程的区别:通过抢占式调度
内核态异步编程:内核线程(轻量级进程LWP,用户可操作的内核态线程)
大量内核态线程会干扰内核调度 影响其他应用
go的调度器分为:内核线程M,P内核处理器,G goroutine 协程 用户态线程
通过P,把无限多的G均分到有限的M上。
Java 第三方协程框架
2.currentHashMap
https://my.oschina.net/pingpangkuangmo/blog/817973
https://blog.csdn.net/qq_33256688/article/details/79938886
1.7之前是头插,1.8之后是尾插
hashmap为了避免尾部遍历,链表插入使用头插,不然rehash要每次都遍历到链表尾。
头插会死循环,因为如果2个线程在rehash,
线程1:原来[3]->3->7,保存的next是7.挂起
线程2已经rehash好了变成[3]->7->3
线程1恢复,开始rehash,变成new[3]->3 next = 7 继续变成[3]->7->3。并且线程2已经把7->3连好了,现在next还是3,变成[3]->3->7->3 3.next还是7死循环
问题在于,本来从链表头部拿,next一定会拿到null,但是另外一个线程使next倒置,导致线程1先rehash好了后面的节点,然后原链表继续next实际上已经在新链表里了。
不能为null
hashmap也是尾插 保留了顺序,不会死循环。
currentHashMap原理:1.7分段锁,降低锁定程度,1.8CAS自旋锁
value 和 next都是volatile
是强一致的,1.7是弱一致,1.7的next是final的只能头插
读不加锁,写如果数组位置为空,CAS添加,如果不空,对头节点加锁并尾插。
扩容会置位,其它线程一起帮助扩容。
3.CAS算法原理?优缺点?
CAS 流程:线程在读取数据时不进行加锁,在写回数据时,比较原值是否修改,如果未被其它线程修改,则写回,不然重新读取。
乐观认为并发操作不是总会发生。
通过操作系统原语实现,保证操作过程中不会被中断。
https://juejin.im/post/5ba66a7ef265da0abb1435ae
非阻塞算法:一个线程的失败或者挂起不会导致其他线程也失败或者挂起。
无锁算法:算法的每个步骤,都存在某个线程能执行下去。多个线程竞争CAS总有一个线程胜出并继续执行。
CAS 是实现非阻塞同步的计算机指令,它有三个操作数,内存位置,旧的预期值,新值,
对于多个状态变量的场景,通过AtomicReference包装这个对象,每次更新先获取旧值,再创建新值,用这两个值进行CAS原子更新。
CAS 实现原子操作的三大问题
1) ABA问题 解决:用AtomicStampedReference 不可变对象pair
2)循环CPU开销 JVM pause指令 Unsafe.park()遇到线程中断不会抛异常,会立刻返回再次运行,CPU可能飙升,一直是RUNNABLE。
3)多个共享变量 解决:用AtomicReference
线程安全的链表
1.静态内部类Node
2.Node.next是AtomicReference<Node
3.需要dummy,还有AtomicReference<Node
4.put操作,CAS中获取尾节点curtail = tail.get()和尾节点的next指针tailnext = tail.next.get()并保存,
4.1判断当前尾节点==tail.get(),但是刚刚保存的tailnext不为空。说明有线程put还没完成tail的修改,需要用CAS机制判断现在的taill是不是curTail并且修改成刚刚保存的next实现推进。
4.2如果没有冲突,next就是null,用CAS尝试插入新节点如果成功再尝试CAS把尾节点变成新节点。
AQS利用CAS原子操作维护自身的状态,结合LockSupport对线程进行阻塞和唤醒从而实现更为灵活的同步操作。
MCS自旋锁 基于链表 公平自旋锁 在本地属性变量上自旋
CLH自旋锁 基于链表 公平自旋锁 在前驱结点上自旋
有N个线程 L个锁 空间需要O(L+N)
4.AQS
AQS:队列同步器
AQS的核心思想是基于volatile int
state这样的一个标志位1表示有线程占用,其它线程需要进入同步队列
同步队列是一个双向链表,当获得锁的线程等待条件,进入等待队列(可以有多个),满足后重新进入同步队列,获取锁竞争
Unsafe类提供CAS方法
同时配合Unsafe工具对其原子性的操作来实现对当前锁的状态进行修改。private volatile int state;ReentrantLock用来表示所有者重复获取该锁的次数Semaphore表示剩余许可数量FutureTask用于表示任务状态(现在FutureTask不用AQS了)但也是state
当线程尝试更改AQS状态操作获得失败时,会将Thread对象抽象成Node对象 形成CLH队列,LIFO规则。
5.线程池的运行流程,使用参数以及方法策略
https://juejin.im/entry/59b232ee6fb9a0248d25139a#%E6%80%BB%E7%BB%93
线程池中的线程包装成工作线程Worker放在HashSet中,Worder继承AQS实现了不可重入锁,Worker的run方法是for循环一直take队列中的runable对象执行
运行流程:
1)如果运行的线程小于corePollsize,则创建核心线程,即使其他是空闲的。
2)当线程池中线程数量>corePollsize,判断缓冲队列是否满,没满放入队列,等待线程空闲执行。
如果队列满了,判断是否达到最大线程数,没达到创建新线程,如果达到了,执行拒绝策略。 只有当workQueue满才去创建新线程处理任务 !!先判断队列再判断最大线程数
3)如果没有空闲,任务封装成Work对象放到等待队列
4) 如果队列满了,用handler指定的策略 (5种)ctl 状态值(高3位)和有效线程数(29位)
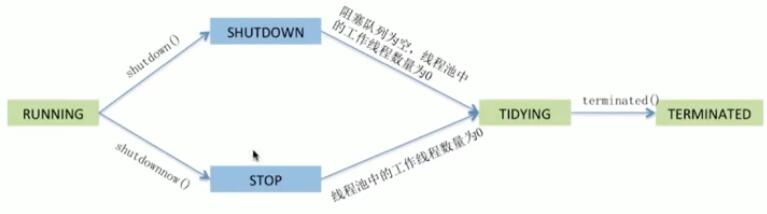
线程池的状态:
RUNNING: 能接受提交
SHUTDOWN: 不能提交,但是能处理。
STOP: 不接受提交也不处理
TIDYING: 所有任务都已经终止 有效线程数为0
TERMINATED: 标识
一共有5种线程池:
1)fixed 无界队列缓冲队列,适用于任务数量不均匀,内存压力不敏感,系统负载敏感。
只要线程个数比核心线程个数多并且当前空闲则回收
2)cached 核心0,最大INT_MAX,缓冲队列:synchronousQueue只要没有空闲线程就会新建(没有队列缓冲)不限制线程数,低延迟短期任务。处理大量短时间工作任务 长期闲置的时候不会消耗资源
3)sigle 1个线程,异步执行,保证顺序执行多个任务
4)scheduled 定时、周期工作调度
最大线程数是Integer.MAX_VALUE,
空闲工作线程生存时间是0,
阻塞队列是DelayedWorkQueue,是堆 按延迟时间获取任务的优先级,里面的任务一定要实现Delayed接口,实现了Conparable接口
ScheduledFutureTask实现了Comparable接口,是按照任务执行的时间来倒叙排序的
5)newWrokStealingPoll 工作窃取,固定并行度的多任务队列,适合任务执行时长不均匀
6.如何优化线程池参数
1.核心线程数 2.最大线程数
3.4 线程的空闲时间(可以通过allowcorethreadtimeout方法允许核心线程回收)
5 缓冲队列ArrayBlockingQueue 有界队列 LinkedBlockingQueue 无界队列 SynchronousQueue 同步队列没有缓冲区
6.线程工厂方法,用于定制线程的属性 例如线程的group,线程名 优先级
7.线程池满时的拒绝策略4种Abourt异常(默认) Discard 抛弃 callerruns 提交者执行 discardoldest 丢弃最早
怎么配置参数
7.线程同步的方法
1.CAS 2.synchronize 3.Lock
synchronize 可重入
对象头 Monitor(管程) 分三块:entry set,owner,wait set
https://blog.csdn.net/javazejian/article/details/72828483
正确说法:给调用该方法的【对象】加锁。在一个方法调用结束之前,其他线程无法得到这个对象的控制权。
方法同步通过ACC_SYNCHRONIZED
代码块同步通过monitorenter monitorexit
缺点:只能实现方法级别的排他性,不能保证业务层面(多个方法)。
Synchronized的锁优化机制
JVM提供了3种Monitor实现:偏向锁、轻量级锁、重量级锁
偏向锁(默认):优先同一线程获取锁,JVM在对象头上Mark word设置线程ID,用CAS操作。
轻量级锁:有另外线程试图锁定已经偏向锁的对象,JVMrevoke撤销偏向锁。
如果失败,短暂自旋。轻量级锁用CAS试图获得锁操作Mark Work,如果成功就轻量级锁,如果失败重量级锁。
notify和wait
notify方法调用后不会释放锁!
放置在sychronized作用域中,wait会释放synchronized关联的锁阻塞,
实现存库为1的生产者消费者。
wait和sleep的不同
1.wait是object类,sleep是thread类
2.wait会释放对象锁,sleep不会
3.wait需要在同步块中使用,sleep可以在任何地方使用
4.sleep要捕获异常,wait不需要
join 方法
join(long millis)
获取t2的对象锁,
判断t2是否alive,
放弃对t2的锁,将当前t3放入t2的【等待池】中,
等待t2notify,一个线程结束后会调用notifyAll,
被notify后会进入t2的锁池等待竞争锁
wait(0)是一直等待1
2
3
4
5
6
7
8
9
10
11
12Thread t3 = new Thread(new Runnable() {
public void run() {
try {
// 引用t2线程,等待t2线程执行完
t2.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("t3");
}
});
如果没有判断isAlive,join的线程根本没启动会永远等待下去
10.1信号量 Semaphore : 管理多线程竞争
例子:100个线程抢10个数据库连接。
10.2 Condition : 线程通信 多个阻塞队列线程间通信
目的:Condition 可以在多线程中创建多个阻塞队列。
例子1:实现 【仓库数量>1】 的生产者消费者:
将生产者和消费者放入不同的阻塞队列,精准控制。
生产者判断full满就阻塞,加入商品后唤醒所有阻塞empty的消费者线程。
Condition
1)由Lock对象生成
2)await 会释放锁,阻塞。 signal能唤醒。 wait和notify只能建立一个阻塞队列。
10.3锁 Lock
ReentreantLock
1)可中断 2)可定时轮询 3)锁分段,每个链表节点用一个独立的锁,多线程能对链表的不同部分操作。
4)公平性/非公平性
5)tryLock,得不到锁立即返回
读写锁 适合读并发多写并发少,读不用互斥另一个方法是copyonwrite
Sync继承AQS,
公平锁新来的线程有没有可能比同步队列中等待的线程更早获得锁。
5)可重入Thread.currentThread()
可重入是如何实现的?
6)业务锁
同一个账户的存钱、取钱业务应该先完整完成一次后才释放锁。
Lock可以跨方法锁对象:登录加锁,登出释放。tryLock如果获取锁失败会立刻返回 false,不会阻塞。
读写锁
降级:获得写入锁能不能不释放获得读取锁。
升级:一般不支持,因为两个读线程同时升级为写入锁,会死锁。
非公平锁(默认):写线程降级为读线程可以,不能从读线程升级为写。
公平锁:如果读线程持有,写线程请求,其他读线程都不能去锁,直到写完。
用处:包装map、linkedhashmap等,在put前后上写锁,get上读锁。
StampedLock 使用CLH的乐观锁 防止写饥饿
1.8新加。是单独的类型,不可重入,锁不是持有线程为单位的。
问题:读写锁使得读和读可以完全并发,但是读锁会完全阻塞写锁。
思路:试着先修改,然后通过validate方法确认是否进入了写模式,如果进入,则尝试获取读锁。
读操作不需要等写操作完。
StampedLock 是乐观锁,
写锁long stamp = .writeLock,.unlockWrite
读锁long stamp = .tryOptimisticRead() , .validate(stamp) .unlockRead(stamp 还可以强行时候悲观读
实现:基于CLH锁:自旋锁,维护一个等待队列,保证没有饥饿并且FIFO。用一个volatile long表示写锁、当前正在读取的线程数量。
8.JMM java内存模型
线程工作内存,保存主内存副本拷贝。线程对变量的所有读取、赋值都必须在工作内存完成,不能直接读写主内存变量。
线程之间的共享变量存储在主内存(main emory)中,每个线程都有一个私有的本地内存(local memory),本地内存中存储了该线程以读/写共享变量的副本。
共享对象存储在主存,一个CPU中的线程读取主存数据到CPU缓存,然后对共享对象做了更改,但CPU缓存中的更改后的对象还没有flush到主存,此时线程对共享对象的更改对其它CPU中的线程是不可见的。最终就是每个线程最终都会拷贝共享对象,而且拷贝的对象位于不同的CPU缓存中。
处理并发过程中的原子性、可见性、有序性。
volatile 内存屏障
https://www.zhihu.com/question/65372648
1.可见性
2.指令重排序
借助了 StoreLoad 实现了CPU本地数据的写回,保持了变量全局可见性。
volatile可以保证变量会直接从主存读取,而对变量的更新也会直接写到主存
变量定义了8种操作顺序的规则,能保证代码执行的顺序与程序顺序相同。保证long和double不被拆分。
定义了8个happen before原则
1)单线程控制流程序次序 2)管程 3)volatile 4)线程启动、5终止、6中断 7)对象finalize 8)传递性
为什么要padding
cache伪共享:多个线程读写同一个缓存行,volatile变量无关但是多个线程之间仍然要同步。
把热点数据隔离在不同的缓存行
8个原子操作
主内存变量线程独占:
1)lock 线程独占,
同个线程可以lock多次,会清空工作内存中这个变量的值执行引擎use前要load assign
2)unlock 释放,之前会同步回主存
主内存->工作内存:
3)read 从主内存读入工作内存
4)load 将read的变量存入工作内存的变量副本
工作变量和执行引擎:
5)use 工作内存变量传递给执行引擎
6)assign 执行引擎赋值给工作变量
工作内存->主内存
7)store 工作内存传入主内存
8)write 将store的值放入主内存
9.快速失败fail-fast 和 安全失败 fail-safe
快速失败:迭代器遍历过程中,集合对象修改会改modCount,和expected不一样,报错。java.util包下的集合类都是 快速失败的。
安全失败:遍历是先拷贝在遍历。遍历过程中的修改不会影响迭代器,不会报错。java.util.concurrent包下都是安全失败。
ThreadLocal 使用弱引用的Map保存变量 线程数据隔离
LinkedBlockingQueue
直接交接队列SynchronousQueue不使用缓存,没有空闲线程就开线程,需要限定好线程池最大数量。
atomic
9.redis
1.redis高性能的原因
1)内存
2)单线程
3)网络请求io单进程多路复用
“多路”指的是多个【网络连接】,“复用”指的是复用同一个【线程】。
采用多路 I/O 复用技术可以让单个线程高效的处理多个连接请求(尽量减少网络 IO 的时间消耗),且 Redis 在内存中操作数据的速度非常快,也就是说内存内的操作不会成为影响Redis性能的瓶颈,主要由以上几点造就了 Redis 具有很高的吞吐量。
2.redis持久化
持久化方式:
1)快照 Mysql Dump和Redis RDB 2)写日志 Mysql Binlog Hbase Hlog Redis AOF
RDB是保存数据库中的键值对,AOF保存redis执行的命令。
RDB
RDB是压缩过的二进制文件,会生成临时文件,把老的RDB文件替换掉。
BGSAVE不会阻塞服务器进程,会创建子进程创建RBD文件。copy-on-write策略,但是父进程写入还会做副本 内存开销大。
触发机制:从节点全量复制主节点会生成RDB文件。 debug reload 、 shutdown。
缺点磁盘性能,宕机没快照的丢了。但是恢复速度快。
AOF
AOF更新频率通常比RDB高。
写【命令】先从redis 写到硬盘缓冲区 再根据3种策略(everysec每秒,always,no(操作系统自己刷))fsync到硬盘AOF文件。
AOF会开子进程重写。
3.redis主从复制
数据是单向的。可以通过slaveof 或者配置方式slave-read-only yes实现。
进入redis用info replication可以查看主从状态
老版本当从节点slaveof之后发送PSYNC,并发送自己的ID
主节点bgsave向从节点发送rdb文件,设置offset,
将偏移量之后的数据存在定长有界队列【积压缓冲区1M】中,一个字节一个offset。
从节点发送offset给主节点继续从缓冲区同步。
之后命令传播。
主从复制(副本)集群是为了解决多请求,读写分离,高可用,
分布式是为了解决一个请求的多个步骤。
redis主从同步的问题
master挂了,从节点全部得全量复制,复制风暴
redis集群一致性hash如何解决分布不均匀
全量复制
1)第一次是全量复制full resync master会BGSAVE。
2)从节点的数据全部清除Flushing old data,通过网络接受RDB文件,加载RDB文件到内存。info server |grep run
3)在同步期间master的写命令会单独记录,rdb同步完后通过偏移同步给slave。
可以看到redis实例的run_id。如果从复制的主节点的id发生变化,则需要全量复制。
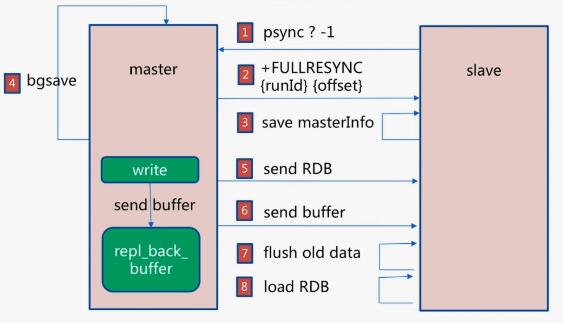
部分复制
info replication 可以看到master的偏移量master_repl_offset和slave的偏移量slave_repl_offset,主节点可以看到各个从节点的偏移量。
偏移量主比从大表示主写入了数据还没同步到从。
如果主从连接断了,先重连,从服务器发送runid和offset,主服务器发送buffer中的部分数据。
4.redis 高可用 sentinel
https://juejin.im/post/5b7d226a6fb9a01a1e01ff64
功能:监控、通知、自动故障转移。客户端应用 在初始化时连接的是 Sentinel 节点集合,从中获取 主节点 的信息。
一个sentinel收不到ping叫主观下线,其它sentinel超过半数也收不到ping叫客观下线。
然后选举,从节点复制。
如果没有半数,客观下线移除,主观下线sentinel收到ping也移除。
Sentinel 无法保证 强一致性
5.Redis分片/Redis集群/Redis分布式
cluster meet ip port
每个节点会维护一个clusterState,里面有clusterNode *slot[16387]数组,当A meet B的时候,
A会把B创建一个Node加在state dict *node里。
B收到后也会创建A的Node添加到state。发送pong
A收到pong发送ping。
然后A用Gossip协议让A知道的其他node都向B发meet。
接收到命令的计算key属于哪个槽,只要O(1)时间查询state就知道是不是本node负责的key,不是就负责路由。发送Moved让客户端自动转向。
clusterState里还有zskiplist *slots_to_key 用跳跃表score是槽的号码,记录所有键值,就可以用范围查询每个slot的key
添加or删除节点只会影响到这个点逆时针遇到的第一个节点之间的所有数据节点受影响
6.redis写失败怎么办
更新数据库,缓存删除失败
方法1:
将需要删除的key发送到消息队列,发送给自己,继续消费,重新向redis删除。
方法2:
订阅数据库binlog
(2)数据库会将操作信息写入binlog日志当中
(3)订阅程序提取出所需要的数据以及key
(4)另起一段非业务代码,获得该信息
(5)尝试删除缓存操作,发现删除失败
(6)将这些信息发送至消息队列
(7)重新从消息队列中获得该数据,重试操作。
mysql中有现成的中间件叫canal,可以完成订阅binlog日志的功能
7.redis常用数据结构
string, hash,set,sorted set,list1
2
3
4
5
6
7
8
9
10redis> GEOADD Sicily 13.361389 38.115556 "Palermo" 15.087269 37.502669 "Catania"
(integer) 2
redis> GEODIST Sicily Palermo Catania
"166274.1516"
redis> GEORADIUS Sicily 15 37 100 km
1) "Catania"
redis> GEORADIUS Sicily 15 37 200 km
1) "Palermo"
2) "Catania"
redis>
8.redis 底层数据结构
redis底层有7种数据结构
9.字典
字典dict 一般情况下, 字典只使用 ht[0] 哈希表, ht[1] 哈希表只会在对 ht[0] 哈希表进行 rehash 时使用。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16typedef struct dict {
// 类型特定函数
dictType *type;
// 私有数据
void *privdata;
// 哈希表
dictht ht[2];
// rehash 索引
// 当 rehash 不在进行时,值为 -1
int rehashidx; /* rehashing not in progress if rehashidx == -1 */
} dict;
其中哈希表是 指向 dict.h/dictEntry 结构的指针1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16typedef struct dictht {
// 哈希表数组
dictEntry **table;
// 哈希表大小
unsigned long size;
// 哈希表大小掩码,用于计算索引值
// 总是等于 size - 1
unsigned long sizemask;
// 该哈希表已有节点的数量
unsigned long used;
} dictht;
用链地址法+头插
因为 dictEntry 节点组成的链表没有指向链表表尾的指针, 所以为了速度考虑, 程序总是将新节点添加到链表的表头位置(复杂度为 O(1)), 排在其他已有节点的前面。
根据 BGSAVE 命令或 BGREWRITEAOF 命令是否正在执行, 服务器执行扩展操作所需的负载因子并不相同, 这是因为在执行 BGSAVE 命令或 BGREWRITEAOF 命令的过程中, Redis 需要创建当前服务器进程的子进程, 而大多数操作系统都采用写时复制(copy-on-write)技术来优化子进程的使用效率, 所以在子进程存在期间, 服务器会提高执行扩展操作所需的负载因子, 从而尽可能地避免在子进程存在期间进行哈希表扩展操作, 这可以避免不必要的内存写入操作, 最大限度地节约内存。
另一方面, 当哈希表的负载因子小于 0.1 时, 程序自动开始对哈希表执行收缩操作
在 rehash 进行期间, 每次对字典执行添加、删除、查找或者更新操作时, 程序除了执行指定的操作以外, 还会顺带将 ht[0] 哈希表在 rehashidx 索引上的所有键值对 rehash 到 ht[1] , 当 rehash 工作完成之后, 程序将 rehashidx 属性的值增一。
随着字典操作的不断执行, 最终在某个时间点上, ht[0] 的所有键值对都会被 rehash 至 ht[1] , 这时程序将 rehashidx 属性的值设为 -1 , 表示 rehash 操作已完成。
要在字典里面查找一个键的话, 程序会先在 ht[0] 里面进行查找, 如果没找到的话, 就会继续到 ht[1] 里面进行查找
在渐进式 rehash 执行期间, 新添加到字典的键值对一律会被保存到 ht[1] 里面, 而 ht[0] 则不再进行任何添加操作: 这一措施保证了 ht[0] 包含的键值对数量会只减不增, 并随着 rehash 操作的执行而最终变成空表。
10.跳跃表
跳跃表中的所有节点都按分值从小到大来排序。沿途访问过的所有层的跨度累计起来, 得到的结果就是目标节点在跳跃表中的排位。
添加节点:程序都根据幂次定律 (power law,越大的数出现的概率越小) 随机生成一个介于 1 和 32 之间的值作为 level 数组的大小, 这个大小就是层的“高度”。
跳跃表的删除:
11.redis set的整数集合
https://zcheng.ren/sourcecodeanalysis/theannotatedredissourceintset/#%E6%B7%BB%E5%8A%A0%E5%85%83%E7%B4%A0
Intset 用于有序、无重复地保存多个整数值contents = [1, 2, 3];如果encode是int16,
如果添加65536,就要把encode升级成int32,
encoding 属性的值为 INTSET_ENC_INT16 , 表示整数集合的底层实现为 int16_t 类型的数组, 而集合保存的都是 int16_t 类型的整数值。
length 属性的值为 5 , 表示整数集合包含五个元素。
contents 数组按从小到大的顺序保存着集合中的五个元素。
因为每个集合元素都是 int16_t 类型的整数值, 所以 contents 数组的大小等于 sizeof(int16_t) 5 = 16 5 = 80 位。
查找是 O(log n) 的,插入和删除都是 O(n)
12.redis 有序集合
skiplist和dict会共享元素的成员和分值。
zset中的dict创建了一个从成员到分值的映射,程序可用O(1)的时间查找到【分值】(zscore)。
跳跃表实现zrank,zrange 还有查找全是logN
13.redis动态字符串sds的优缺点
结构:1)len 2)free 3)char[] buf数组
优点
1)以\0结尾,可以复用c string的库函数。
2)O(1)复杂度获取长度
3) 杜绝缓冲区溢出 (c如果没分配够空间就直接覆盖了)
4) 减少内存重分配(空间预分配和惰性空间释放)
5)二进制安全(可以存图片等特殊格式),c字符串中不能包含空字符。
14. redis内存碎片怎么管理
info可以看到1
2
3
4used_memory:1038744104 # 分配的内存,redis数据内存占用
used_memory_rss:5811122176 # 进程占用的物理内存总量
mem_fragmentation_ratio:5.59 # used_memory_rss/used_memory比值,内存碎片率
mem_allocator:libc
大于1说明是碎片多 <1说明物理内存到swap了,可能会变得很卡。
Redis有自己的内存分配器,当key-value对象被移除时,Redis不会马上向操作系统释放其占用内存
Redis的内存主要包括:对象内存+缓冲内存+自身内存+内存碎片。
可选的分配器有jemalloc、glibc、tcmalloc默认jemalloc
出现高内存碎片问题的情况:大量的更新操作,比如append、setrange;大量的过期键删除,释放的空间无法得到有效利用
解决办法:数据对齐,安全重启(高可用/主从切换)。
内存溢出策略:默认拒绝写入。LRU对有超时时间的,LRU对所有key,随机对超时/所有key。
redis的每个obj会记录lru时间。还有应用计数。
现在有碎片整理功能了1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21 Enabled active defragmentation
碎片整理总开关
activedefrag yes
Minimum amount of fragmentation waste to start active defrag
内存碎片达到多少的时候开启整理
active-defrag-ignore-bytes 100mb
Minimum percentage of fragmentation to start active defrag
碎片率达到百分之多少开启整理
active-defrag-threshold-lower 10
Maximum percentage of fragmentation at which we use maximum effort
碎片率小余多少百分比开启整理
active-defrag-threshold-upper 100
Minimal effort for defrag in CPU percentage
active-defrag-cycle-min 25
Maximal effort for defrag in CPU percentage
active-defrag-cycle-max 75
15.redis事务
https://redisbook.readthedocs.io/en/latest/feature/transaction.html
EXEC的时候执行事务队列中的所有命令:除非当前事务执行完毕,否则服务器不会中断事务,也不会执行其他客户端的其他命令。
软工和测试
白盒测试是什么
怎么评价一个软件系统的好坏
47 linux 怎么查询一个端口
linux shell
删除正在读写的文件
lsof -n | grep deleted 然后kill -9 PID
每个文件都有 2 个 link 计数器 —— i_count 和 i_nlink。
i_count 是内存引用计数器,i_nlink 是硬盘引用计数器。
当文件被某个进程引用时,i_count 就会增加;当创建文件的硬连接的时候,i_nlink 就会增加。
rm 操作只是将 i_nlink 置为 0 了;由于文件被进程引用的缘故,i_count 不为 0,所以系统没有真正删除这个文件。
i_nlink 是文件删除的充分条件,而 i_count 才是文件删除的必要条件。
有进程打开了这个大文件,却没有关闭这个文件的句柄,那么linux内核还是不会释放这个文件的磁盘空间,最后造成磁盘空间占用100%
恢复被删除的正在写的文件
恢复那个删除的文件。
例如,你删除了tcpdump.log,执行lsof | grep tcpdump.log,你应该能看到这样的输出:
tcpdump 2864 tcpdump 4w REG 253,0 0 671457 /root/tcpdump.log (deleted)
然后:
cp /proc/2864/fd/4 /root/tcpdump.log
如何传文件 scp
如何查进程
ps -ef |grep
如何在文件找查一个字符串grep 'abc' abc.txtgrep 'abc' abc*从abc开头的文件查找
参数-o只输出正则匹配的部分
参数-v输出不含正则的内容
遍历文件夹查找所有文件中的一个字符串的所有行grep -r "要查找的内容" ./
文件夹大小:du -sh .
如果grep不带文件就等输入
echo不支持标准输入
- 如何查找一个文件 find默认是递归查找的
find ~ -name "abc.java
sed 替换
awk 切片统计
终端 /dev/tty当前终端
vi: ZZ:命令模式下保存当前文件所做的修改后退出vi;
怎么调整top多久刷新,top间隔默认是多少 默认3秒 top -d
任务队列 和 CPU Load
netstat
列出所有tcp端口 netstat -at
显示pid和进程名netstat -p
可以查看所有套接字的连接情况
top 可以查看到哪些指标
1: CPU 平均负载1min,5min,15min
在一段时间内CPU正在处理以及等待CPU处理的 【进程数】 之和。CPU使用队列的长度的统计信息。
2:进程、cpu状态、内存状态(系统内核控制的内存数)
打开的文件lsof
java的进程通信
管道 Java中没有命名管道1
2
3
4
5
6
7
8// 启动子进程
ProcessBuilder pb = new ProcessBuilder("java", "com.test.process.T3");
Process p = pb.start();
// 或者
Runtime rt = Runtime.getRuntime();
Process process = rt.exec("java com.test.process.T3");
// 子进程的输出
BufferedInputStream in = new BufferedInputStream(p.getInputStream());
共享内存
nio有内存映射文件mmap
https://cloud.tencent.com/developer/article/10318601
2
3
4
5RandomAccessFile raf = new RandomAccessFile("D:/a.txt", "rw");
FileChannel fc = raf.getChannel();
// 核心 系统调用mmap
MappedByteBuffer mbb = fc.map(MapMode.READ_WRITE, 0, 1024);
FileLock fl = fc.lock();//文件锁
mmap和共享文件的区别
操作系统划分出一块内存来共多个进程共享使用
mmap需要把内容写回到文件,所以还需要与文件打交道;而SM则是完全的内存操作,不涉及文件IO,效率上可能会好很多。还有就是SM使用的系统调用是shmget和shmctl。
FileChannel 是将共享内存和磁盘文件建立联系的文件通道类。
信号1
2
3
4
5
6
7
8
9OperateSignal operateSignalHandler = new OperateSignal();
Signal sig = new Signal("SEGV");//SEGV 这个linux和window不同
Signal.handle(sig, operateSignalHandler);
public class OperateSignal implements SignalHandler{
public void handle(Signal arg0) {
System.out.println("信号接收");
}
}
线程池 参数,常用的
callable
11.C++虚函数作用及底层实现
虚函数是使用虚函数表和虚函数表指针实现的。
虚函数表:一个类 的 虚函数 的 地址表:用于索引类本身及其父类的虚函数地址,如果子类重写,则会替换成子类虚函数地址。
虚函数表指针: 存在于每个对象中,指向对象所在类的虚函数表的地址。
多继承:存在多个虚函数表指针。
12.千万数据的表怎么优化
表设计:
SQL优化:
1)超过500w要分表
分表方案:水平分表(时间、id、hash)、垂直分表
数据按照某种规则存储到多个结构相同的表中,例如按 id 的散列值、性别等进行划分
水平切分的实现:
Merge存储引擎允许将一组使用MyISAM存储引擎的并且表结构相同(即每张表的字段顺序、字段名称、字段类型、索引定义的顺序及其定义的方式必须相同)的数据表合并为一个表,方便了数据的查询。1
2
3
4
5
6CREATE TABLE log_merge(
dt DATETIME NOT NULL,
info VARCHAR(100) NOT NULL,
INDEX(dt)
) ENGINE = MERGE UNION = (log_2004, log_2005, log_2006, log_2007)
INSERT_METHOD = LAST;
2)Explain
索引设置
3)减少查询列
应用层优化
4)减少返回的行 limit
5)拆分大的delete和insert,不然会一次锁住很多数据
如果明确知道只有一条结果返回,limit 1 能够提高效率
sql优化 计算两点距离
100公里以内的餐馆,不要查询圆,查询方形
两个between,如果第一列是范围查询,无法索引后面的列,所以只能索引第一个列。
13.
15.基于比较的算法的最优时间复杂度是O(nlog(n))
因为n个数字全排列是n! 一次比较之后,两个元素顺序确定,排列数为 n!/2!
总的复杂度是O(log(n!)) 根据斯特林公式就等于O(nlog(n))
18 没有中序没办法确定二叉树
前序 根左右
后序 左右根
找不到左右的边界
20 数据库三范式
目的:减少冗余、插入删除更新异常
第一范式:列不可拆分 目的:列原子性
第二范式:每个属性要【完全依赖】于主键,如果主键有多个候选键,属性
第三范式:非主键关键字段之间不能存在依赖关系,避免更新、插入、删除异常。每一列都要与主键直接相关。【消除传递依赖】。
例子: 各种信息只在一个地方存储,不出现在多张表中。 如果成员表已经有部门编号,不应该有部门表中的部门名称。
BCNF:表的部分主键依赖于非主键部分 应该拆分。
第四范式:两个均是1:N的关系,当出现在一张表的时候,会出现大量的冗余。所以就我们需要分解它,减少冗余。
20 数据库 5约束
主键约束PRIMARY KEY - NOT NULL 和 UNIQUE 的结合。
唯一约束UNIQUE 默认值约束DEFAULT 非空约束NOT NULL 外键约束FOREIGN KEY CHECK (CHECK (P_Id>0))
!唯一索引不能有重复空串,但是把所有空串变成NULL就可以了
20 自然连接 NATURAL JOIN
columns with the same name of associate tables will appear once only.
自然连接是指关系R和S在所有公共属性(common attribute)上的等接(Equijoin). 但在得到的结果中公共属性只保留一次, 其余删除.
控制文件:Oracle服务器在启动期间用来标识物理文件和数据库结构的二进制文件
24 生产者消费者问题(消费的是同一个东西) 1个互斥2个同步
P表示-1,V表示+1
事件关系:
1)互斥:缓冲区是临界资源,需要互斥访问
2)同步:缓冲区满,生产者等待消费者取 (先后顺序)
3)同步:缓冲区空,消费者等生产者生产 (先后)
信号量机制:一个关系一个信号量
1)互斥信号量初始化为1
2)缓冲区同步的信号量根据系统资源初始值设定
1)生产者:空闲缓冲区数量 信号量初始值empty = n
2)消费者:缓冲区产品数量 初始值full = 0
互斥信号量是在同一个进程之间操作的。
一前一后同步关系 ,两个信号量的PV操作在不同的进程
生产者:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18product(){
while(1){
P(empty)
P(mutex)
//放入缓冲区
V(mutex)
V(full)
}
}
custom(){
while(1){
P(full)
P(mutex)
// 取出
V(mutex)
V(empty)
}
}
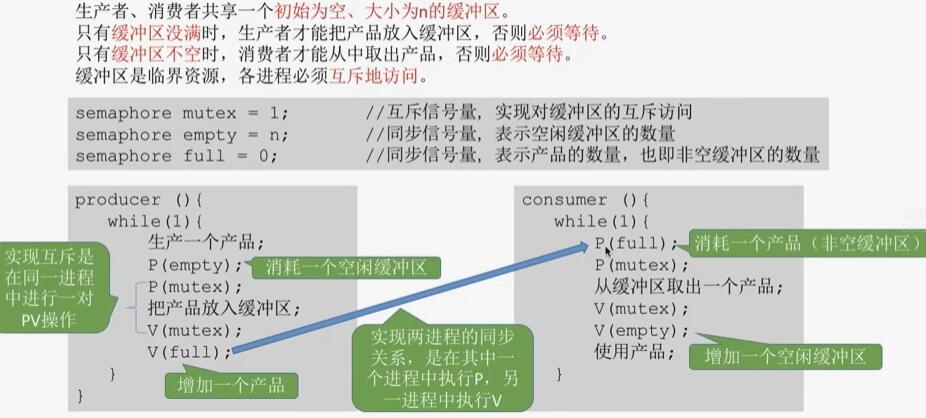
注意点:
1)对于P操作 一定要先操作同步信号量再操作互斥信号量,不然互斥加锁然后同步阻塞 循环等待 就死锁了。 V操作顺序无所谓
2)生产和使用操作不要放到PV操作(临界区)里面,时间太多
25 多生产者 多消费者 (一个临界区,但是生产者和消费者有特定类型)
例子:只有一个盘子,父亲-儿子之间生产-消费 苹果,母亲-女儿之间生产-消费 橘子
关系:
1)互斥:盘子
2)同步:父亲儿子 消费-生产
3)同步:母亲女儿 消费-生产
4)同步:盘子空(事件) 之后 放入水果
事件信号量:
1)互斥1
2)盘子中的苹果 0
3) 盘子中的橘子 0
4)盘子中的剩余空间 1
注意:
1)如果盘子资源为1,不用加互斥,剩余空间就可以用来互斥了
2)如果盘子资源为2以上,不加互斥会数据覆盖
26 读者-写者问题 count计数器
1)允许多个读
2)只许一个写
3)完成写之前不允许读/写
4)写之前要没有读/写操作
关系:
1)互斥:写-写
2)互斥:写-读(第一个读进程要对文件加锁)(最后一个进程解锁)
信号量:
1)互斥 是否有进程在访问文件 semaphore rw = 1
2) 当前有几个读进程在访问 int count = 0
3)互斥count:隐藏3 mutex = 1 因为判断是不是第一个和计数不原子,所以判断+增加要加锁
问题:实际上是读优先。读进程太多会导致写进程饿死
改进:用信号量semaphore w = 1;1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33semaphore rw = 1 // 文件互斥
int count = 0 // 读进程计数
semaphore mutex = 1 // count计数互斥
semaphore w = 1 // 写进程优先
writer(){
while(1){
P(w)
P(rw)
// 写文件
V(rw)
V(w)
}
}
reader(){
while(1){
// 如果前一个读执行到释放w后,
// w会被写抢走,下一个读会等待写完成
P(w)
// 用于count互斥访问
P(mutex)
if(count == 0)
P(rw)
count++
V(mutex)
// 写会抢走
V(w)
P(mutex)
count--
if(count == 0)
V(rw)
V(mutex)
}
}
不是疯狂写优先。是读写公平的。先来先服务的。
27 哲学家问题 两个临界资源 防止死锁
5个哲学家 5个筷子 拿起左然后右吃饭
方法1:只允许4个人吃饭(初始值为4的信号量)
方法2:奇数号的先拿左边,偶数号的先拿右边
方法3:用一个信号量同时对拿左边拿右边加锁
28 银行家算法(避免死锁) 安全序列 不会死锁
手里有100亿钱,A要最多借70,B最多借40,C最多借50,借完了就会全部还回来。现在已经分别借了ABC一些,ABC其中一个再发起了一个请求,应不应该借?
银行家算法:每次分配资源之前,判断是否会进入不安全状态(可能会产生死锁(没钱借又拿不会钱)
找安全序列:
用剩余资源 遍历所有进程 还需资源,如果可以分配,则分配+拿回全部资源+加入安全序列+从遍历中移除,再从头遍历所有进程。
31 虚拟内存 页面置换算法
OPT:知道后面会访问什么。向之后看,之后最后出现/没出现的的先删除
缺页中断
页面置换(满了才换)
缺页率:缺页次数/请求次数
FIFO:Belady异常。
LRU:如果满了,将内存块中的数值向前找,最早出现的那个删除。
CLOCK:时钟置换算法,NRU最近未用算法。 循环队列。 访问位。
问题
LRU:出现一次冷数据批量查询,误淘汰大量热点数据
LFU:起始频率值低,导致最近新加入的数据总会很容易被剔除
FIFO:特殊领域:作业调度、消息队列
33 ajax的四个步骤
1)创建xhr对象
2)open方法参数:method,url,同步或异步
3)send
4)注册一个监听器onreadystatechange readyState=4和status200 获得响应.responseText
34 XSS攻击,跨站脚本攻击
网站没有对用户提交数据进行转义处理或者过滤不足的缺点,进而添加一些恶意的脚本代码(HTML、JavaScript)到Web页面中去,使别的用户访问都会执行相应的嵌入代码。
解决方法:
1)cookie设置成http Only 不让前端document.cookie拿到
2)对输入多做一些检查 对 html危险字符转义
CSRF 盗取用户cookie或者session伪造请求
1)每次提交加随机数token
2)检查referer
35 防止表单重复提交
1)submit方法最后把按钮disable掉
2)用token
3)重定向
39异常 Error 和 Exception的区别
派生于Error或者RuntimeException的异常称为unchecked异常,所有其他的异常成为checked异常
1)Error是JVM负责的
2)RuntimeException 是程序负责的
3)checked Exception 是编译器负责的
异常处理机制:
在堆上创建异常 try catch中有return之前都会先执行finally的return
java进程间通信
java 线程通信:wait notify,共享变量的synchronize,Lock同步机制
全局变量
2个线程之间的单向数据连接 NIO pipe 写sink 读source。
java线程同步的方法
45 布隆过滤器
黑名单
如果数据量有8G,hash冗余要保证16G
构造:使用16/8 = 2G 可以表示16G个bit位。
set:用8个随机函数,得到0-16G中8个随机数,并将这8位设置为1。
get:同样用这8个随机函数,查看这8位是否都为1。
46 精确的接口限流。
/禁止重复提交:用户提交之后按钮置灰,禁止重复提交
如果做到精确5秒里只能访问10次
漏桶法 流量整形
个固定容量的漏桶,按照常量固定速率流出水滴
令牌桶(对业务的峰值有一定容忍度)
固定容量令牌的桶,按照固定速率往桶里添加令牌
前端做还是后台做
大数据相关的
内存管理算法
页内碎片:已分配的块但是分大了的
页外碎片:
内核内存管理算法:伙伴系统:分离适配算法 将内存外碎片问题转化成内存内碎片问题
按2的幂次划分成空闲快链表
1.内存管理的数据结构:位图(等长划分)、空闲区表(起始地址、长度、标志),空闲区链表
内存分配算法:分配给进程+记录为新的空闲区
首次适配、下次适配、最佳适配、最差适配
48 操作系统 进程通信
进程和线程的区别
1)地址空间 线程的内存描述符 将直接指向 父进程的内存描述符 ,打开的资源
2)通信,全局变量:线程通信要加锁
3)调度和切换:切换快。
4)进程不是可执行的实体
文件是进程创建的信息逻辑单元
每个进程有专用的线程表跟踪进程中的线程。和内核中的进程表类似。
进程结构:代码段、数据段、堆栈段
代码段:多个进程运行同一个程序,可以使用同一个代码段。
数据段:全局变量、常量、静态变量。
栈:用于存放 【函数调用】,存放函数的 【参数】,函数内部的【局部变量】
PCB位于核心堆栈的底部。进程组ID是一个进程的必备属性。
进程切换:
保存处理机上下文,包括程序计数器和其他寄存器
更新PCB信息
把进程的PCB移入相应队列,如就绪、在某事件阻塞队列
选择另一个进程执行,并更新PCB
更新内存管理的数据结构
恢复处理机上下文
子进程:
当调用fork时,子进程完全复制了父进程地址空间的内容,包括:堆、栈、数据段,并和父进程共享代码段,因为代码段是只读的,不会被修改。
在Linux上,对于多进程,子进程继承了父进程的下列哪些?
A 进程地址空间
B 共享内存
C 信号掩码
D 已打开的文件描述符
E 以上都不是
子进程对数据段和堆、栈段的修改不会影响父进程。
“写时复制”:现在fork不会立刻复制,当子进程要修改的时候才会分配进程空间 并复制。
创建一个守护进程
java守护线程JVM的垃圾回收、内存管理等线程都是守护线程。
Main退出,前台线程执行完毕,后台线程也直接结束了。生命周期
终端:系统与用户交互的界面,运行进程的终端被称为 【控制终端】。
控制终端关闭时,进程都会关闭,除了守护进程。
1)fork()一个子进程并退出父进程。
子进程拷贝了父进程的
【会话期、进程组、控制终端、工作目录、父进程的权限掩码、打开的文件描述符】。
2)在子进程中创建会话setid()让进程摆脱1)原会话2)进程组3)控制终端 的控制。
3)工作目录换成根目录chdir("/")
4)文件权限掩码设置成0 umask(0)
5)关闭所有打开的文件描述符
僵尸进程
子进程退出,父进程没有调用wait,子进程的进程描述符仍然在系统中。父进程应该调用wait取得子进程的终止状态。
如果父进程退出,僵尸进程变成孤儿进程给init(1)进程,init会周期性调用wait清除僵尸进程。
49 线程之间什么是共享的
1)地址空间2)全局变量3)打开文件4)子进程5)即将发生的定时器6)信号与信号处理程序6)账户信息
线程试图实现:共享同一组资源的多个线程的执行能力
50 栈为什么要线程独立
一个栈帧只有最下方的可以被读写,处于工作状态,为了实现多线程,必须绕开栈的限制。
每个线程创建一个新栈。多个栈用空白区域隔开,以备增长。
每个线程的栈有一帧,供各个被调用但是还没有从中返回的过程使用。
该栈帧存放了相应过程的局部变量、方法参数、过程调用完成后的返回地址,线程私有不共享。
例如X调用Y,Y调用Z, 执行Z时,X和Y和X使用的栈帧会全部保存在堆栈中。
每个线程有一个各自不同的执行历史。
栈内存分配运算内置于处理器的指令集中,效率很高
运行时在模块入口时,数据区需求是确定的。
栈是编译器可以管理创建和释放的内容,堆需要GC
栈很少有碎片
cpp
1.引用和指针
https://www.nowcoder.com/ta/review-c/review?tpId=22&tqId=31356&query=&asc=true&order=&page=34
1、指针有自己的一块空间,而引用只是一个别名;
2、使用sizeof看一个指针的大小是4,而引用则是被引用对象的大小;
3、指针可以被初始化为NULL,而引用必须被初始化且必须是一个已有对象的引用;
4、作为参数传递时,指针需要被解引用才可以对对象进行操作,而直接对引用的修改都会改变引用所指向的对象;
5、可以有const指针,但是没有const引用;
6、指针在使用中可以指向其它对象,但是引用只能是一个对象的引用,不能 被改变;
7、指针可以有多级指针(**p),而引用至于一级;
8、指针和引用使用++运算符的意义不一样;
9、如果返回动态内存分配的对象或者内存,必须使用指针,引用可能引起内存泄露。
用引用返回一个函数值的最大好处是,在内存中不产生被返回值的副本。
2.静态全局变量、静态局部变量
https://www.nowcoder.com/ta/review-c/review?tpId=22&tqId=31342&query=&asc=true&order=&page=20
static的最主要功能是隐藏,其次因为static变量存放在静态存储区,所以它具备持久性和默认值0。
1.全局变量:源程序作用域。
所有未加static前缀的全局变量和函数都具有全局可见性,其它的源文件也能访问extern
函数的定义和声明在默认情况下都是extern的,但静态函数只是在声明他的文件当中可见,不能被其他文件所用。
2.静态全局变量:文件作用域。
如果加了static,就会对其它源文件隐藏。不能用extern导出。
例如在a和msg的定义前加上static,main.c就看不到它们了。利用这一特性可以在不同的文件中定义同名函数和同名变量,而不必担心【命名冲突】。
全局变量、静态全局变量存储在静态数据区。只有程序刚开始运行时唯一一次初始化。
3.静态局部变量:static局部变量只被初始化一次,下一次依据上一次结果值。
!!! 单例模式!!!
作用域:作用域(可见性)仍为局部作用域,当定义它的函数或者语句块结束的时候,作用域随之结束。1
2
3
4
5
6
7
8
9
10
11
12
13class Singleton
{
private:
Singleton(){}
Singleton(const Singleton &s);
Singleton & operator = (const Singleton &s);
public:
static Singleton * GetInstance()
{
static Singleton instance; //局部静态变量
return &instance;
}
};
注:当static用来修饰局部变量的时候,它就改变了局部变量的存储位置,从原来的栈中存放改为静态存储区。但是局部静态变量在离开作用域之后,并没有被销毁,而是仍然驻留在内存当中,直到程序结束,只不过我们不能再对他进行访问。
局部变量改变为静态变量后是改变了它的存储方式即改变了它的【生存期】。
把全局变量改变为静态变量后是改变了它的【作用域】,限制了它的使用范围。
4.static【函数】作用域只在本文件
从原来的栈中存放改为【静态存储区】。但是局部静态变量在离开作用域之后,并没有被销毁,而是仍然驻留在内存当中,直到程序结束,只不过我们不能再对他进行访问。
可在当前源文件以外使用的函数,应该在一个头文件中说明,要使用这些函数的源文件要包含这个头文件.
静态存储区:内存在程序编译的时候就已经分配好
已经初始化过的全局变量在.data段,而未初始化的全局变量在.bss段。
.bss段不占用可执行文件的大小,而是在加载程序的时候由操作系统自动分配并初始化为0
3.目标文件
从文本文件到可执行文件的过程:
预处理阶段:对源代码文件中文件包含关系(头文件)、预编译语句(宏定义)进行分析和替换,生成【预编译文件】。
编译阶段:将经过预处理后的预编译文件转换成特定汇编代码,生成【汇编文件】
汇编阶段:将编译阶段生成的汇编文件转化成机器码,生成【可重定位目标文件】
链接阶段:将多个目标文件及所需要的库连接成最终的【可执行目标文件】
用于二进制文件、可执行文件、目标代码、共享库和核心转储 的标准文件格式。
分为3种:
1)可重定位的目标文件 .o文件 .a静态库文件 未链接 可以经过链接生成可执行的目标文件和可被共享的目标文件。
没有程序进入点。
2)可执行的目标文件 链接处理之后的
3)可【共享】的目标文件 .so。 动态库文件。
4.析构函数不能抛出异常
https://www.cnblogs.com/fly1988happy/archive/2012/04/11/2442765.html
C++异常处理模型有责任清除那些由于出现异常所导致的已经失效了的对象(也即对象超出了它原来的作用域),并释放对象原来所分配的资源, 这就是调用这些对象的析构函数来完成释放资源的任务,所以从这个意义上说,析构函数已经变成了异常处理的一部分。
在对象的构造过程中,或许由于系统资源有限而致使对象需要的资源无法得到满足,从而导致异常的出现,但析构函数完全是可以做得到避免异常的发生,毕竟你是在释放资源呀!
把异常完全封装在析构函数内部,决不让异常抛出函数之外
const
const是函数类型的一部分,在实现部分也要带该关键字。
常成员函数不能更新类的成员变量,也不能调用该类中没有用const修饰的成员函数,只能调用常成员函数。
对于类的常成员函数的描述正确的是
正确答案: A 你的答案: D (错误)
常成员函数不修改类的数据成员
常成员函数可以对类的数据成员进行修改
常成员函数只能由常对象调用
常成员函数不能访问类的数据成员
前向申明
类A要将类B的对象(或者指正)作为自己的成员使用,并且类B将类A的对象(或者指针)作为自己可以访问的数据,那么这个时候要在a.h中include b.h,同时在b.h 中要include a.h,但是相互包含是不可以的,这个时候就要用到类的前向声明了。
可以用于定义指向这个类型的指针和引用。
java static
static方法不能被覆盖override:因为方法覆盖是运行时动态绑定的,static是编译时静态绑定的。
setAccessible()
https://www.jianshu.com/p/2bc886dd7a8a
Hashtable 和 HashMap的区别
Hashtable不允许键或者值是null
hashMap线程不安全,遍历的时候会有环死循环
Hashtable 不能支持符合操作:若不存在则添加、若存在则删除,即使单个方法加锁,符合方法也线程不安全。
currentHashMap cas无锁,不涉及上下文切换效率高。
1.7版本分为16个segment分段锁,允许16个线程同时读写操作不同的段。
ArrayList
每次扩容1.5倍int newCapacity = oldCapacity + (oldCapacity >> 1);
线程不安全,扩容的时候会发生数组越界
LinkedList
LinkedList比ArrayList更占内存,因为LinkedList为每一个节点存储了两个引用.
Comparable和Comparator接口 区别
Comparable 是该类支持排序 实例具有内在的排序关系 不能跨越不同类型的对象比较
Comparator 是外部比较器,需要一个非标准的排序关系。有多个域,按不同的域排序。加了很多default方法。
Enumeration接口和Iterator接口 的区别
Enumeration快
Iterator允许调用者删除底层集合里面的元素
finalize 方法
JNI(Java Native Interface)调用non-Java程序(C或C++),finalize()的工作就是回收这部分的内存。
任何对象的finalize只会被调用一次
final finally finalize的区别
final的方法不能被重写
Exception和Error的区别
事务是什么
数据库并发控制的基本单位。
一个类里面有两个方法A和B,方法A有@Transaction,B没有,但B调用了A,外界调用B会不会触发事务?
51ThreadPoolExecutor 怎么实现的
1)线程池状态
ExecutorService 源码
52 Java多继承
https://juejin.im/post/5a903ef96fb9a063435ef0c8#heading-1
内部类:每个内部类都能独立地继承自一个(接口的)实现,内部类允许继承多个非接口类型.
socket编程
mq有几种模式
Binding:Exchange和Queue的虚拟连接
接口和抽象类的区别
抽象类里面能不能有非抽象方法 能不能被重写
String不能被继承
重写和重载的区别
53 sb依赖注入控制反转。
IOC:控制反转
控制:Java Bean的生命周期(创建、销毁)
反转:容器管理依赖关系。
IOC是一种设计模式。将对象-对象关系解耦和对象-IOC容器-对象关系。容器管理依赖关系。依赖对象的获得被反转了。调用者不用创建被调用的实例,容器管理单例对象。
IOC的实现方式:
1)设置注入/属性注入setter方法
2)构造器注入
3)工厂方法注入
依赖注入DI方式:把底层类作为参数传递给上层类,实现上层对下层的“控制”。
setter、接口、构造函数。
组件之间依赖关系由容器在运行期决定。
SpringBoot Autowired是自动注入,自动从spring的上下文找到合适的bean来注入
IOC容器初始化
1)Resource定位
2)载入:把定义的Bean表示成IOC的数据结构(不包括Bean依赖注入)
3)注册到容器的HashMap中
IOC容器通过和注解配置(Controller)
1)IOC容器就是ApplicationContext 可以通过web.xml或者加载xml或者文件用application-context.xml初始化。
2)定义bean 然后getBean()就获取了对象可以调用方法了
bean的作用域6种 默认是单例,多次getBean是同一个。prototype每次都是新的。
bean有创建和销毁的回调函数。
3)如果要用两个类的组合,一个类里需要new另一个类,这样那个类的构造参数都需要在这个类里面改,这样强耦合。所以这个外部对象应该用构造函数(强依赖)/setter(可选依赖(可配置的(颜色)))等方法注入。
通过配置文件的方法,注入依赖的参数。
Bean生命周期
实例化bean测试结果:先构造函数——>然后是b的set方法注入—— >InitializingBean 的afterPropertiesSet方法——>init- method方法
教科书上总结为:
一、Spring装配Bean的过程
- 实例化;
- 设置属性值;
- 如果实现了BeanNameAware接口,调用setBeanName设置Bean的ID或者Name;
- 如果实现BeanFactoryAware接口,调用setBeanFactory 设置BeanFactory;
5.如果实现ApplicationContextAware,调用setApplicationContext设置ApplicationContext - 调用BeanPostProcessor的预先初始化方法;
- 调用InitializingBean的afterPropertiesSet()方法;
- 调用定制init-method方法;
- 调用BeanPostProcessor的后初始化方法;
Spring容器关闭过程
- 调用DisposableBean的destroy();
- 调用定制的destroy-method方法;
注解的本质
注解的本质就是一个继承了 Annotation 接口的接口1
2public interface Override extends Annotation{
}
解析一个类或者方法的注解往往有两种形式,一种是编译期直接的扫描,一种是运行期反射。
@Override 注解,编译器就会检查当前方法的方法签名是否真正重写了父类的某个方法,也就是比较父类中是否具有一个同样的方法签名。
JAVA 中有以下几个『元注解』:
@Target:注解的作用目标
@Retention:注解的生命周期
@Documented:注解是否应当被包含在 JavaDoc 文档中
@Inherited:是否允许子类继承该注解
Springboot的启动流程
tomcat的启动流程
Tomcat的基本架构和组件,以及请求的整个流程
一个server有多个service,一个service表示多个连接器和一个容器的绑定,容器是分Engine、Host、Context、Wapper层的,连接器负责处理协议和IO包装成内部request发给容器,Engine找到负责的容器,每个容器都有责任链和链上的处理器,并启动下一容器的执行流。这个web应用有独立的类加载器。隔离WEB-INF下的jar包。
另外还有线程池模块,每个请求都会分配一个县城处理。
Spring 怎么解决循环引用
Lazy和setter方法注入
有状态的bean都使用Prototype作用域,无状态的一般都使用singleton单例作用域。
构造器循环依赖:通过使用bean创建时的标识值
setter循环依赖:通过引入objectfactory解决
Spring容器整个生命周期内,有且只有一个对象,所以很容易想到这个对象应该存在Cache中,Spring为了解决单例的循环依赖问题,使用了三级缓存。1
2
3
4
5
6
7
8/** Cache of singleton objects: bean name --> bean instance */
private final Map<String, Object> singletonObjects = new ConcurrentHashMap<String, Object>(256);
/** Cache of singleton factories: bean name --> ObjectFactory */
private final Map<String, ObjectFactory<?>> singletonFactories = new HashMap<String, ObjectFactory<?>>(16);
/** Cache of early singleton objects: bean name --> bean instance */
private final Map<String, Object> earlySingletonObjects = new HashMap<String, Object>(16);
singletonFactories : 单例对象工厂的cache
earlySingletonObjects :提前暴光的单例对象的Cache
singletonObjects:单例对象的cache
AOP 面向切面编程 关注点分离,抽离业务逻辑
知识图谱 之间的关系 和结构存储neo4j
vue的特点
和react的比较
54 前后端跨域怎么实现
跨域并不是请求发不出去,请求能发出去,服务端能收到请求并正常返回结果,只是结果被浏览器拦截了。
http://www.ruanyifeng.com/blog/2016/04/cors.html
无法获取非同源的Cookie、LocalStorage、SessionStorage等
无法获取非同源的dom
无法向非同源的服务器发送ajax请求
cookie跨域:
默认情况下,浏览器向不同域的发送ajax请求,不会携带发送cookie信息
CORS请求默认不发送Cookie和HTTP认证信息。如果要把Cookie发到服务器,一方面要服务器同意,指定Access-Control-Allow-Credentials字段。
Access-Control-Allow-Credentials: true
另一方面,开发者必须在AJAX请求中打开withCredentials属性。
var xhr = new XMLHttpRequest();
xhr.withCredentials = true;
否则,即使服务器同意发送Cookie,浏览器也不会发送。或者,服务器要求设置Cookie,浏览器也不会处理。
但是,如果省略withCredentials设置,有的浏览器还是会一起发送Cookie。这时,可以显式关闭withCredentials。
xhr.withCredentials = false;
cookie的属性path和domain
浏览器的同源策略导致了跨域。
1)JSONP 但是只能直接发get请求<script src="http://127.0.0.1:8897"><script>
2)Access-Control-Allow-Origin':'*'
3)nginx反向代理
XSS 跨站脚本攻击:篡改网页,注入恶意html脚本。
CSRF 跨站请求伪造(利用用户登陆态)
Cookie的 SameSite属性strict
http缓存
响应:
Expires是日期
Cache-Control 的no-cache每次都要验证(ctrl+F5强制刷新)
mag-age是给浏览器,s-max-age是给代理
Etag不是秒,一秒修改很多次的情况,比较版本号
条件式:
过期了会带条件询问
请求if-modified-since- 响应Last-modified 304
用户的cookie无法缓存,post和put都不缓存
Vary 加上对应的头信息,匹配才使用缓存
55 cookies
1) 存储 浏览器的cookie数据库中
2)服务器产生
3)会威胁客户隐私
4)用于跟踪用户访问和状态
cookie有两种:会话cookie(退出浏览器删除, 没设置discard或者expires 或者max-age) 持久cookie
cookie的实现
cookies 安全性
cookies设置同源策略
服务器传送cookie时设置属性secure为true,表示创建的cookie只能在HTTPS连接中被浏览器传递到服务器端进行会话验证,如果是HTTP连接则不会传递该信息,所以很难被窃听到。
服务器传送cookie时设置属性HttpOnly
cookie加密
原本需要由web服务器创建会话的过程转交给Spring-Session进行创建,本来创建的会话保存在Web服务器内存中,通过Spring-Session创建的会话信息可以保存第三方的服务中,如:redis,mysql等
redis string
redis
如果一个千万条数据的表怎么优化
数据库分片:
1)分片ID
2)无需分片的表
序列化的性能
短链接
特征模型
归并排序
多线程归并排序
线程上下文类加载器
JNDI服务,使用线程上下文加载器,父类加载器请求子类加载器完成类加载。
OSGi自定义加载器,程序模块和它的类加载器一起替换掉。
运行时字节码生成 动态代理
动态代理:原始类和接口还未知的时候就确定了代理类的代理行为。
代理类与原始类脱离直接联系后,可以用于不同的应用场景。
jvm以byte数组为单位拼接出 传入接口的每个方法的实现,并且调用外部传入this的invoke方法,的字节码文件。
RCU机制
http://blog.jobbole.com/107958/
分布式锁
1)互斥性:保证不同节点的线程之间互斥2)同一个节点同一个线程可重入3)支持超时防死锁for update悲观锁 大并发不建议
数据库是各个服务进程的临界资源。如果已经下订单了还没减库存,但是没加锁就会脏读。
乐观锁:因为查询加行锁开销比较大,用版本号,查询出版本号之后update或者delete的时候需要判断当前的版本号和刚才读的是否一致,这样就不用for update
ZooKeeper是以Paxos算法为基础分布式应用程序协调服务。
锁过期强依赖于时间,但是ZK不需要依赖时间,依赖每个节点的Session。
redis分布式锁
流程1)setnx(key,currenttime+timeout)2)expire(key)3)业务执行完后del(key)
其他tomcat获取不到锁返回0流程
1)get(key)判断当前时间和value的时间,
2)如果key超时了可以先get再setgetset(key,currenttime+timeout) 如果get的值是null或者和之前的锁一样(?)继续expire(key)走加锁流程…
面向对象和面向过程的区别
封装:隐藏内部代码
继承:复用现有代码
多态:改写对象行为
面向过程是结构化开发方法,面向数据流的开发方法,用数据流图建立系统的功能模型。自顶向下,逐层分解,适合数据处理领域,难以适应需求变化。每个模块确定输入输出。
结构化方法包括了:结构化分析SA,结构化设计SD(转换成软件体系结构图),结构化程序设计SPD
结构化设计包括:体系结构设计、数据设计、接口设计(内部和外部接口)、过程设计
面向对象:UML是标准建模语言。面向对象分析,面向对象设计、面向对象实现,界限不明显。
面向对象= 对象+分类+继承+消息通信
需求经常变化,但是客观世界的对象和对象与对象间的关系比较稳定,所以OO的结果也相对稳定。
完整表述现实世界的数据结构,表达数据间的嵌套、递归联系。
封装性和继承性提高了软件可重用性。
面向过程会导致结构体里出现不是本模块的成员
对象的产生方式有
1)原型对象(prototype 原型链)为基础的 (所有对象都是实例)
2)基于类(Java)的对象模型。
面向对象6大原则
1.单一指责s 2.开闭原则o 3.里氏替换原则l
4.依赖倒置D:
模块间的依赖通过抽象发生,实现类之间不发生直接的依赖关系,其依赖关系是通过接口或抽象类产生的。即依赖抽象,而不依赖具体的实现。
5.接口隔离I:客户端不应该依赖它不需要的接口 6.迪米特原则L:一个对象应该对其他对象有最少的了解
分布式文件系统HDFS
1)每个文件拆分成很多小块128M(并行处理和负载均衡).
2)文件以多副本存储(副本因子),高可用。
3)有一个节点存储着存储信息 1个Master,NameNode。N个Slave DataNode。
NameNode:1)处理客户端请求 文件系统的读写操作 2)元素据
DataNode:1)块的存储和操作 2)定期心跳
分布式文件系统一致性
HDFS 文件只能写1次 除了 append和truncate 而且不能多并发写。
节点失效
为什么本地文件系统不使用hash
2.25匹马,5个跑道,每个跑道最多能有1匹马进行比赛,最少比多少次能比出前3名?前5名?
5轮找出各组第一;5组第一跑一次,得出第一,只有前3的组可能是前3;最后一次A2, A3, B1, B2, C1参赛得出第二第三名。
13.100亿个整数,内存足够,如何找到中位数?内存不足,如何找到中位数?
topK问题
1.找出N个数中最小的K个数
大小为K的【大根堆】。好处,不用全部读入内存。时间复杂度NlogK
2.从N个有序数组/队列找到最小的K个值
用每个队列最小的元素组成一个N个元素的【小根堆】,获取堆顶,将堆顶这个元素的队列的下一个元素放入堆,重复,直到堆有K个数。
算法复杂度是(N+K-1)*logK
分布式
1)均衡负载技术
均衡负载的算法有:随机 round roubin 一致性hash
2)容灾设计
3)高可用系统
CAP
CP的系统其实不少,最典型的就是分布式数据库,如Redis、HBase等。对于这些分布式数据库来说,数据的一致性是最基本的要求,因为如果连这个标准都达不到,那么直接采用关系型数据库就好,没必要再浪费资源来部署分布式数据库。
rpc通信
jsonrpc没法区分int和long
通信开销
加密和压缩
秒杀项目相关
https://mp.weixin.qq.com/s/ktq2UOvi5qI1FymWIgp8jw
秒杀项目的请求流程
需求:秒杀地址隐藏,记录订单,减库存
1.下订单和减库存如何保持一致?
ACID强一致性,利用关系型数据库的强一致性,【订单表和库存表】放在一个关系型数据库事务,实时一致性。
高并发场景提高关系型数据库吞吐量和存储,应该吧库存和订单放入同一个数据库分片。
主从复制只能提高数据库读。
BASE思想:分布式事务拆分,每个步骤都记录状态,使用【写前日志】或者数据库来记住任务的执行状态,一般通过行级锁实现比写前日志更快。
2.缓存与数据库一致性
读请求和写请求串行化,串到一个内存队列里去。串行化就不会不一致。
先更新数据库再删除缓存。
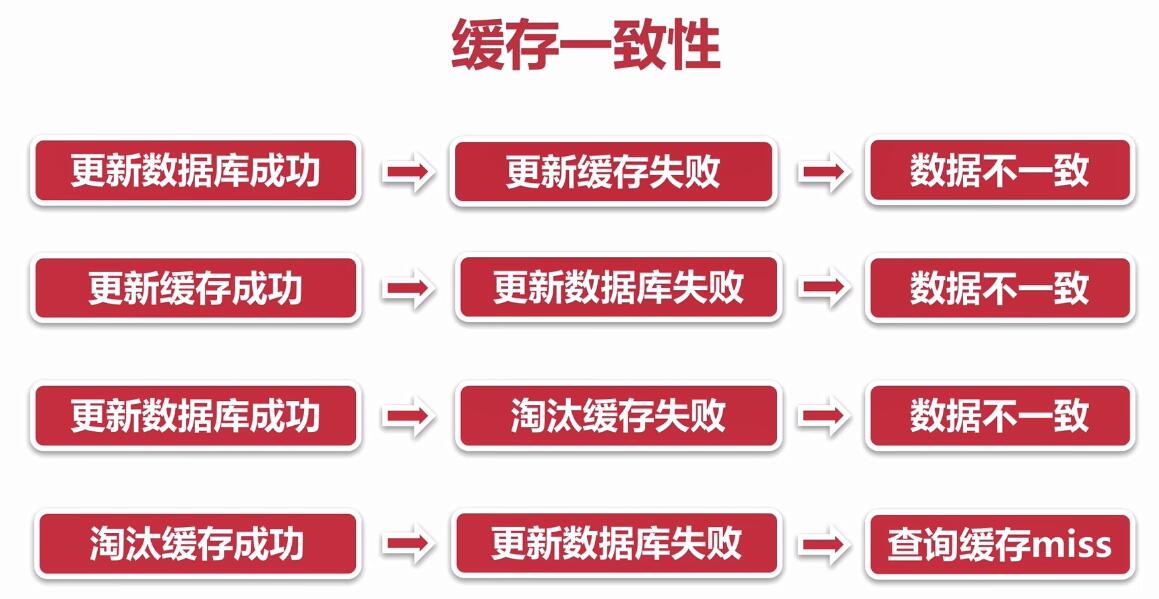
缓存更新的时候加锁 防止大量请求直接访问数据库雪崩或者缓存不一致
常用的缓存使用模式
Cache Aside
同时更新缓存和数据库,
!先更新数据库,【删除缓存】,下次使用会添加到缓存
这种模式不保证 数据库和cache的一致性!
数据库中的数据可以随时被外部进程修改,但是cache不会变。
如果数据库是有备份的,经常同步问题会很严重。
出问题的场景只有并发读和写,读在写之前读到数据库,在写返回删除缓存之后,读请求返回写旧缓存。基本不可能发生。
可以通过2PC或者PAXOS保证一致性,实际操作还是设置过期时间。
(并发操作包装成一个事务?)
数据库被外部进程修改的场景:
mysql读写分离:
如果先删除缓存,请求B从从库查询,但是还没完成主从同步,旧值写入缓存。
解决方案是 异步延迟删除,保证读请求完了再删除。
如果删除缓存失败!!cache中是旧数据。
1.失效时间 2.mq重试
3.二次删除效率低
解决方案还是binlog
各个应用实例一定要用同样的分布式缓存。
适用场景:数据是不变的,可以启动时预加载的
Read/Write Through:
先更新缓存,缓存负责同步更新数据库
读:Cache Aside是由调用方负责把数据加载入缓存,而Read Through则用缓存服务自己来加载,从而对应用方是透明的。
写:当有数据更新的时候,如果没有命中缓存,直接更新数据库,然后返回。如果命中了缓存,则更新缓存,然后再由Cache自己更新数据库(这是一个同步操作)
1 每次写缓存都更新
2 写缓冲,下一次写强制刷新
Write Behind Cacheing:
linux文件系统的page cache
只更新缓存,缓存定期异步更新数据库
write-behind 缓存中,数据的读取和更新通过缓存进行,与 write-through 缓存不同,更新的数据并不会立即传到数据库。
相反,在缓存中一旦进行更新操作,缓存就会跟踪脏记录列表,并定期将当前的脏记录集刷新到数据库中。
缓存会合并这些脏记录。只保证最后一次更新。
会出现一瞬间cpu负载变高
redis怎么保证缓存一致性
更新cache成功,更新数据库失败怎么办?强一致性,你需要使用“两阶段提交协议
3.更新数据库的同时为什么不是马上更新缓存而是删除缓存
更新数据库后更新缓存可能会因为多线程下导致写入脏数据(比如线程A先更新数据库成功,接下来要取更新缓存,接着线程B更新数据库,但B又更新了缓存,接着B的时间片用完了,线程A更新了缓存) (?)
4.缓存穿透:数据库中没这个数据,缓存中也没有,数据库被大量查询
有很多种方法可以有效地解决缓存穿透问题,最常见的则是采用布隆过滤器,将所有可能存在的数据哈希到一个足够大的bitmap中,一个一定不存在的数据会被这个bitmap拦截掉,从而避免了对底层存储系统的查询压力。
哈希表槽位数(大小)的改变平均只需要对 K/n个关键字重新映射,其中K是关键字的数量, n是槽位数量。
1)查询结果为空的也缓存(命中不高 但是频繁更新的数据)
2)对可能为空的key统一存放(命中不高 更新不频繁)
3)如果后面插入了新数据要删除相应缓存(或者设置较短超时时间)
缓存击穿
热点数据key过期,大量访问数据库
1)用分布式锁,保证只有一个线程从数据库拉取数据
2)后台异步脚本更新key过期时间
缓存雪崩
缓存不可用(宕机) 大量缓存key失效
多级缓存、随机超时、提高可用性
5.数据库乐观锁减库存
先查库存,在减库存的时候判断当前库存是否与读到的库存一样
乐观锁适用冲突少的情况,会导致大量回滚 死循环 cpu占用高
乐观锁适合多cpu,进程不放弃cpu空转,而不是切换,等待其它cpu执行完临界区(一般很快)
可重复读两个线程读到一样的值
直接对库存代码加锁,但是多个JVM部署不行
6.读写锁能不能用在大并发场景
7.为什么要把页面放到redis中?
页面缓存,将整个页面手动渲染,加上所有vo,设定有效期1分钟,让用户1看到的是1分钟前的页面
详情页应该不能放(?)库存更新怎么办(?)
只是把页面商品信息放到了redis中
8.秒杀地址 + 接口限流
如果有很多手机账号,公不公平?
按收货地址(?)
9.如果订单表和库存表不在同一个数据库
除了分布式锁更轻量级的做法?消息队列-异步处理
10.为什么秒杀系统需要mq 秒杀排队系统
多redis扣库存
一旦缓存丢失需要考虑恢复方案。比如抽奖系统扣奖品库存的时候,初始库存=总的库存数-已经发放的奖励数,但是如果是异步发奖,需要等到MQ消息消费完了才能重启redis初始化库存,否则也存在库存不一致的问题。
需要一个分布式锁来控制只能有一个服务去初始化库存
11.为什么秒杀系统需要mq 秒杀排队系统
生产者和消费者速率不一样
https://www.infoq.cn/article/yhd-11-11-queuing-system-design
1)削峰:减少瞬间流量。处理失败的消息退回队列,接收的下一条还是这个消息,这是因为消息传递不仅要保证一次且仅一次,还要保证顺序。
2)限流保证数据库不会挂掉,不然会影响其他服务。主要还是为了减少数据库访问 透这么多请求来数据库没有意义,会有大量锁冲突导致读请求会发生大量的超时。如果均成功再放下一批.
3)持久化:就算库存系统出现故障,消息队列也能保证消息的可靠投递confirm模式将状态写入消息db(mysql),不会导致消息丢失。定时将状态失败的任务重新执行。
4)订单和库存解耦.1
2
3
4
5
6
7#从队列里每次取几个
spring.rabbitmq.listener.simple.prefetch= 1
# 消费失败会重新压入队列
spring.rabbitmq.listener.simple.default-requeue-rejected= true
#
spring.rabbitmq.publisher-confirms= true
spring.rabbitmq.publisher-returns= true
多线程处理消息:1
2
3#消费者数量
spring.rabbitmq.listener.simple.concurrency= 10
spring.rabbitmq.listener.simple.max-concurrency= 10
异步下单:
异步下单的前提是确保进入队列的购买请求一定能处理成功。Redis天然是单线程的,其INCR/DECR操作可以保证线程安全。而且入队之前要对用户user+goodsId判重。
假设处理一个秒杀订单需要1s,而将秒杀请求(或意向订单/预订单)加入队列(或消息系统等)可能只需要1ms。异步化将用户请求和业务处理解耦
其他消息中间件
如何用redis list实现mq
生产端可靠性投递:Confirm模式,消费端的幂等
return模式 消息不可达监听 补偿处理
MQ限流 QOS
死信队列,通过exchange路由到死信队列
生产者确认
confirm模式最大的好处在于他是异步的,一旦发布一条消息,生产者应用程序就可以在等信道返回确认的同时继续发送下一条消息,当消息最终得到确认之后,生产者应用便可以通过回调方法来处理该确认消息,如果RabbitMQ因为自身内部错误导致消息丢失,就会发送一条nack消息,生产者应用程序同样可以在回调方法中处理该nack消息。
消费者确认
RabbitMQ会等待消费者显式发回ack信号后才从内存(和磁盘,如果是持久化消息的话)中移去消息。否则,RabbitMQ会在队列中消息被消费后立即删除它。RabbitMQ会一直持有消息直到消费者显式调用basicAck为止。
12.消息中间件的作用
1)解耦 基于数据的接口层
2)冗余(持久化)
3)扩展性 解耦了 处理过程
4)削峰
5)降低进程耦合度
6)顺序消费
7)缓冲
8)异步通信
rabbitMQ 的confirm通知是否持久化成功,ack或者nack方法,等到有千条消息再一次性刷新到磁盘
确保持久化:
1.放到redis , DB,消息状态:发送中
2.投递消息,ack后删除消息
3.定时任务获取redis中的 发送中消息,补偿性投递,补偿次数>3 失败,由人工排查
补偿方案要设计幂等性
乐观锁:操作库存的时候带上商品version
13.mq集群模式
Master-Slave模式
NetWork模式 两组Master-Slave模式
14.mq怎么实现的
https://tech.meituan.com/2016/07/01/mq-design.html
AMQP协议: 虚拟主机(virtual host),交换机(exchange),队列(queue)和绑定(binding)。一个虚拟主机持有一组交换机、队列和绑定.
broker(消息队列服务端)
1)数据流:例如producer发送给broker,broker发送给consumer,consumer回复消费确认,broker删除/备份消息等。
2)RPC:两次RPC发送者把消息投递到服务端(broker),服务端再将消息转发一手到接收端,消费端最终做消费确认的情况是三次RPC。然后考虑RPC的高可用性,尽量做到无状态,方便水平扩展。
3)消息堆积:存储消息,在合适的时机投递消息。
4)广播:我维护消费关系,可以利用zk/config server等保存消费关系。
生产者和消费者是完全解耦.
?因为保证可靠消费?这样redis预减的库存就真的减少到mysql里了?不用再同步回来(?
持久化?
消息队列时需要考虑到的问题,如RPC、高可用、顺序和重复消息、可靠投递、消费关系解析等
直接模式
15. mq的持久化
交换机持久化、队列持久化、消息持久化
持久化包括:队列索引和消息存储,队列索引维护队列中落盘的消息(消息的存储地点,是否已给消费者,是否已被消费者ack)
队列中的消息有4种状态:
alpha 消息和索引都在内存
beta:消息内容在磁盘,索引在内存
gamma:内容在磁盘,索引在磁盘和内存(持久化消息)
delta:内容、索引都在磁盘
内部存储分为5个子队列,经历从内存到磁盘再到内存,消费者从Q4读取。
默认:队列中消息尽可能存在内存中,即使持久化消息,被写入磁盘的同时,内存中也有备份,当需要释放内存时,换页到磁盘会阻塞队列操作。
惰性队列:目标:支持更长队列,更多消息存储,消息存入磁盘,消费者消费到再加载到内存。
流量控制
存储成一个完整的流控链,
Connection处理进程,Channel处理进程,队列处理进程,消息持久化进程
Kafka
高吞吐:顺序读写磁盘可以和内存随机读写速度差不多。
利用了操作系统的page Cache 页缓存缓存消息,避免在JVM内倍垃圾回收STW。
零拷贝减少消息网络传输时间。
同一主题多分区存储。
ES
ES是用什么框架写的
Lucene:只是一个框架,要充分利用它的功能,需要使用JAVA,并且在程序中集成Lucene,学习成本高,Lucene确实非常复杂。
Lucene是Apache的一个全文检索引擎工具包,通过Lucene可以让程序员快速开发一个全文检索功能。Lucene不是搜索引擎,仅仅是一个工具包。
大量导入 translog
https://blog.csdn.net/u013850277/article/details/88904303
https://www.elastic.co/guide/cn/elasticsearch/guide/cn/translog.html
倒排索引的原理
https://zhuanlan.zhihu.com/p/33671444
倒排索引的好处:多关键字查询时,在倒排表中先完成查询的并、交等逻辑运算,把记录查询转换成地址集合的运算,得到结果后再存取记录,提高查找速度。
Lucene提供了5个基础类,Document描述文档,文档有多个属性Field。
Analyzer负责分词、分此后提交给IndexWriter建立索引,并把索引对象持久化到Directory中。(文件系统/内存)。
倒排列表中每个节点存储document地址、文中出现位置、用TF-IDF计算的分数
倒排索引压缩编码
suggest:有3种term、phrase可以修正拼写错误,autocomplete自动补全
term基于编辑距离
phrase基于n-gram方法的短语计算逻辑
autocompletion前缀匹配:数据结构FST,索引过程中创建FST数据结构,并存储在索引种,在需要时载入内存
text会解析生成倒排索引,倒排列表中每个节点存储document地址、文中出现位置、用TF-IDF计算的分数
倒排索引压缩编码
geo-point类型
_search查询类型:
1.简单查询
1.match 会对输入进行分词并在字段中搜索
2.term 查询关键词不会分词
2.1terms 查询批量关键字
3.”match_all”:{} 全查询
4.match_phrase 短语查询,分词后满足所有词的结果,设置slop设置词之间的距离
5.multi_match 可以指定多个字段中query
stored_fields 指定返回的字段
sort 数组存放排序字典
range 指定字段gte lte 范围 boost权重
wildcard 通配符查询
组合查询
布尔查询包括filter,must,should,must_not
(倒排索引会把大写全部转小写(?))
1。关键字全文索引 +其他普通查询 用bool查询+multiquery1
2
3
4
5
6
7
8
9boolQuery.must(
QueryBuilders.multiMatchQuery(rentSearch.getKeywords(),
HouseIndexKey.TITLE,
HouseIndexKey.TRAFFIC,
HouseIndexKey.DISTRICT,
HouseIndexKey.ROUND_SERVICE,
HouseIndexKey.SUBWAY_LINE_NAME,
HouseIndexKey.SUBWAY_STATION_NAME
));
面积范围查询rangeQuery,也添加到boolQuery.filter
具体字段的关键字查询用termQuery,也加到boolQuery.filter
2。自动补全
索引字段类型1
2
3"suggest": {
"type": "completion"
},
填充:对索引中的所有分析字段用分词器在java中手动分词 返回值是List
遍历Token,筛选长度>2的非数字,包装成List
查询:用SuggestBuilder设定字段并搜索关键字和条数,再用search字段搜索,返回值result.getEntries()是CompletionSuggeestion.Entry, .getText().string()可以获得词,记得去重1
2
3
4
5
6
7
8CompletionSuggestionBuilder suggestion = SuggestBuilders.completionSuggestion("suggest").prefix(prefix).size(5);
SuggestBuilder suggestBuilder = new SuggestBuilder();
suggestBuilder.addSuggestion("autocomplete", suggestion);
SearchRequestBuilder requestBuilder = this.esClient.prepareSearch(INDEX_NAME)
.setTypes(INDEX_TYPE)
.suggest(suggestBuilder);
问题:这些suggest都是在每个房子的suggest字段里
好处是一个房子上架下架,这些提示会跟着消失/出现,还应该有一个热词索引单独用来查询
3.聚合1
2
3
4
5
6
7SearchRequestBuilder requestBuilder = this.esClient.prepareSearch(INDEX_NAME)
.setTypes(INDEX_TYPE)
.setQuery(boolQuery)
.addAggregation(
AggregationBuilders.terms(HouseIndexKey.AGG_DISTRICT)
.field(HouseIndexKey.DISTRICT)
).setSize(0);
terms后面要起名。不要数据只要数量
获取结果1
2
3
4
5
6
7SearchResponse response = requestBuilder.get();
if (response.status() == RestStatus.OK) {
Terms terms = response.getAggregations().get(HouseIndexKey.AGG_DISTRICT);
if (terms.getBuckets() != null && !terms.getBuckets().isEmpty()) {
return ServiceResult.of(terms.getBucketByKey(district).getDocCount());
}
}
拓扑排序
DFS:当出度为0的时候将当前点加入栈中,递归到上一层,所有出度都访问过后入栈。缺点是先要判断DAG
可以设置from和size做分页
Redis zset热门统计
https://stackoverflow.com/questions/12846028/how-to-cap-a-leaderboard-in-redis-to-only-n-elements
add的时候调用ZSCORE hot_houre_key 1 houseId
并且移除掉除了最后10个最大的ZREMRANGEBYRANK hot_houre_key 0 -10
get的时候ZREVRANGE hot_houre_key 0 -1 WITHSCORES
tomcat最大线程数
maxThreads规定的是最大的线程数目,并不是实际running的CPU数量;实际上,maxThreads的大小比CPU核心数量要大得多。这是因为,处理请求的线程真正用于计算的时间可能很少,大多数时间可能在阻塞,如等待数据库返回数据、等待硬盘读写数据等。因此,在某一时刻,只有少数的线程真正的在使用物理CPU,大多数线程都在等待;因此线程数远大于物理核心数才是合理的。
BufferedInputStream 的作用不是减少 磁盘IO操作次数(这个OS已经帮我们做了),而是通过减少系统调用次数来提高性能的。
java直接内存
虽然最终也是要从磁盘读取数据,但是它并不需要将数据读取到OS内核缓冲区,而是直接将进程的用户私有地址空间中的一部分区域与文件对象建立起映射关系
https://juejin.im/post/5cb48201f265da03b0515294
操作系统I/O过程中,需要把数据从用户态拷贝到内核态,然后再输出到I/O设备,所以从java堆内存输出到I/O设备需经过两次拷贝,而direct memory在native 堆上,所以只需经过一次拷贝。
内存映射文件属于JVM中的直接缓冲区,还可以通过 ByteBuffer.allocateDirect() ,即DirectMemory的方式来创建直接缓冲区。他们相比基础的 IO操作来说就是少了中间缓冲区的数据拷贝开销。同时他们属于JVM堆外内存,不受JVM堆内存大小的限制。
DirectMemory 默认的大小是等同于JVM最大堆
由 JAVA进程直接建立起 某一段虚拟地址空间和文件对象的关联映射关系,参见 Linux虚拟存储器图中的 “Memory mapped region for shared libraries” 区域,所以内存映射文件的区域并不在JVM GC的回收范围内,
“Memory mapped region for shared libraries” ,这段区域就是在内存映射文件的时候将某一段的虚拟地址和文件对象的某一部分建立起映射关系,此时并没有拷贝数据到内存中去,而是当进程代码第一次引用这段代码内的虚拟地址时,触发了缺页异常,这时候OS根据映射关系直接将文件的相关部分数据拷贝到进程的用户私有空间中去
DirectMemory的内存只有在 JVM执行 full gc 的时候才会被回收
http://www.ruanyifeng.com/blog/2016/08/http.html