我什么要用setnx作分布式啊?完全没必要,使用setex(原子操作) 不就可以了嘛?
- setex 会覆盖之前的设置的 key,返回ok,这样就办法上锁了
过期是以对象为单位,比如一个 hash 结构的过期是整个 hash 对象的过期,而不是其中的某个子 key。
如果一个字符串已经设置了过期时间,然后你调用了 set 方法修改了它,它的过期时间会消失。
MurmurHash算法
输入键有规律 算法仍能给出一个很好的随机分布。
ConcurrentSkipListMap
4.搭建redis服务器
1 | cd /usr/local |
查看配置
config get *
常用API
keys * 查询所有的键,会遍历所有的键值,复杂度O(n)dbsize 查询键总数,直接获取redis内置的键总数变量,复杂度O(1)exists key 存在返回1,不存在返回0 O(1)
ttl 命令可以查看键hello的剩余过期时间,单位:秒(>0剩余过期时间;-1没设置过期时间;-2键不存在)expire key seconds 当超过过期时间,会自动删除,key在seconds秒后过期persist key 去掉过期时间
type key 如果键hello是字符串类型,则返回string;如果键不存在,则返回none
所有key都是字符串

redis 单线程 所以命令会等待
redis 使用epoll模型多路复用 redis自身实现的事件处理 将epoll的读写、连接、关闭转换成自身的事件。不在IO上浪费时间
fysnc file 是独立线程
数据结构
字符串 应用场景: 缓存、计数器、分布式锁
结构: key:value
因为单线程 所以无竞争 线程安全
mget和n次get mget省了很多网络开销 从n网络n命令->1网络n命令 )
)
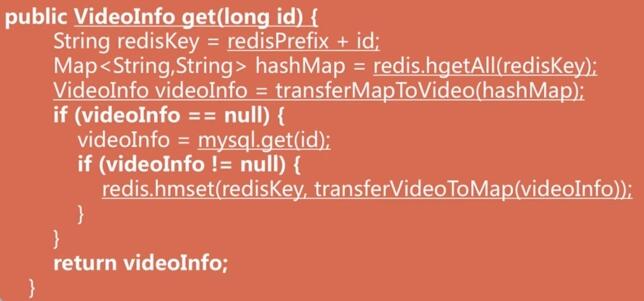
场景1: 缓存视频基本信息redis<->mysql

场景2: 分布式ID生成器
incr id
hash 可以更新属性
用户信息用hash 可以部分更新属性
但是比较难控制过期时间,只能对一个key设置过期时间 不能对一个属性
field 不能相同
结构 key->field,value
id看成是一行,field是列
场景1:记录网站每个用户个人主页的访问量
hincrby user:1:info pageview count
场景2:缓存视频基本信息redis<->mysql
list 列表
key:element 是有序(插入顺序)队列 双端队列 可以获得range
阻塞插入,对空的队列进行pop,不是立刻返回 而是等一段时间拿到最新的弹出
用户生产者消费者模型 消息队列
实现
1.capped collection LPUSH+LTRIM 有固定数量的列表而不是无限放大
2.消息队列 LPUSH + BRPOP
3.stack LPUSH + LPOP
4.queue LPUSH + RPOP
场景1:微博TimeLine 将所有我关注的用户的最新微博按新旧排、分页
每条微博作为一个对象,自己的微博id作为外联key
set 集合
key : values (values不能有)
可以做 inter(共同)\diff\union操作
1 打标签Tag : SADD
2 随机数 :SPOP/SRANDMEMBER
3 社交网络操作 : SADD + SINTER
场景1: 抽奖srandmember,spop
场景2: like 、 点赞 、 踩
场景3: 给用户添加标签,给标签添加用户
zset 有序集合
结构
key : (score:value) value不重复 凭借score排序
可以更新score
场景1: 畅销榜
使用 时间戳、销售量 关注量作为score
同样可以使用集合的交集、并、diff
慢查询
可能发在生命周期4步里的第3步。 1 发送命令 2 排队 3 执行命令 4 返回结果
配置 maxlen 一般设置成1ms 默认10ms
希望一秒执行万次 每条0.1ms 超过1ms就应该记录这条命令了
队列长度一般1000 慢查询定期要持久化1
2
3
4
5127.0.0.1:6379> config get slowlog*
1) "slowlog-log-slower-than"
2) "10000"
3) "slowlog-max-len"
4) "128"
获取慢查询队列1
2slowlog get n
slowlog len # 长度
流水线
redis命令执行时间是微妙
北京-上海 1300km, 光速3x10^8 m/s -> 300 000 km/s
光线速度是2/3光速 = 200 000 km/s
一条命令的传输时间是 (1300x2)/200 000 = 13 ms
m操作是原子的,pipeline不是,还是排队,但是顺序是对的,只能操作在一个redis节点上1
2
3
4
5Pipeline pipeline = jedis.pipelined();
for (int i = 0; i <100 ; i++) {
pipeline.hset("hashkey:"+i,"field"+i ,"value"+i );
}
pipeline.syncAndReturnAll();
发布订阅
角色: 发布者 订阅者 频道
不能消息堆积 现在订阅访问不到以前的1
2
3
4
5
6
7127.0.0.1:6379> publish cloud:tv "hello world"
(integer) 0 # 订阅的人数
127.0.0.1:6379> subscribe cloud:tv
Reading messages... (press Ctrl-C to quit)
1) "subscribe"
2) "cloud:tv"
3) (integer) 1