原子性: 互斥 同一时间只有一个线程操作
atomic
竞争激烈能维持常态,性能比Lock还好,但每次只能同步一个值
AtomicInteger
1 | public final int incrementAndGet() { |
Unsafe:1
2
3
4
5
6
7
8
9
10//var1 当前对象 var2当前值 var4 add值
public final int getAndAddInt(Object var1, long var2, int var4) {
int var5;
do {//调用底层native方法获得var2当前值,有没有别的线程处理
var5 = this.getIntVolatile(var1, var2);
//直到 主存var5和var2工作内存相等,则执行add
} while(!this.compareAndSwapInt(var1, var2, var5, var5 + var4));
return var5;
}
compareAndSwapInt是native方法
LongAdder
与CAS中的AtomicLong比较:AtomicLong竞争激烈时,大概率修改失败,性能差
JVM会将64位的long和double读写会拆成2个32位的操作1
2
3public void increment() {
add(1L);
}
LongAdderextends Striped64实现热点数据分离,高并发时会将long变成一个数组Cell[] as,但是并发更新可能会有误差。
compareAndSet用于AtomicBoolean中
控制代码只执行一次(只能一个线程)。执行之前是false 执行之后true。compareAndSet(false,true)1
2
3
4
5public final boolean compareAndSet(boolean expect, boolean update) {
int e = expect ? 1 : 0;
int u = update ? 1 : 0;
return unsafe.compareAndSwapInt(this, valueOffset, e, u);
}
AtomicBoolean
1 | private static AtomicBoolean isHappened = new AtomicBoolean(false); |
atomic机器级指令
compareAndSet 比锁快,映射到处理器操作。1
2
3largest.updateAndGet(x->Math.max(x,observed));
//或者
largest.accumulateAndGet(observed,Math::max);
大量线程访问相同的原子值LongAdder,LongAccumulator线程个数增加自动提供新的加数。所有工作都完成后才需要总和的情况使用。
AtomicIntegerFieldUpdate
原子性更新类的更新类中相应字段 必须volatile不能static
1 | public class AtomicExample5 { |
AtomicStampReference解决CAS的ABA问题
1 | private static class Pair<T> { |
ABA其它线程将A改成B再改成A,本线程比较发现没有变。
每次更新变量版本号+11
2
3
4
5
6
7
8
9
10
11
12 public boolean compareAndSet(V expectedReference,
V newReference,
int expectedStamp,
int newStamp) {
Pair<V> current = pair;
return
expectedReference == current.reference &&
expectedStamp == current.stamp &&//比较stamp
((newReference == current.reference &&
newStamp == current.stamp) ||
casPair(current, Pair.of(newReference, newStamp)));
}
AtomicLongArray数组,可以更新索引位置的值
long getAndSet(int i, long newValue)boolean compareAndSet(int i, long expect, long update)
锁
synchronized 依赖JVM
不可中断锁,必须等到代码执行完,竞争不激烈使用,可读性好
1.修饰代码块:作用域调用的对象
输出0~9,0~91
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20public class SynchronizedExample1 {
// 修饰一个代码块
public void test1() {
synchronized (this) {
for (int i = 0; i < 10; i++) {
log.info("test1 {} - {}", i);
}
}
}
public static void main(String[] args) {
SynchronizedExample1 example1 = new SynchronizedExample1();
ExecutorService executorService = Executors.newCachedThreadPool();
executorService.execute(() -> {
example1.test1();
});
executorService.execute(() -> {
example1.test1();
});
}
}
2.修饰方法:作用于调用的对象,子类的继承该方法不会带synchronized,需要再声明。因为synchronized不是方法声明的一部分
同上输出0~9,0~91
2
3
4
5public synchronized void test2() {
for (int i = 0; i < 10; i++) {
log.info("test2 {} - {}", i);
}
}
当声明另一个对象,两个线程会交叉执行,不同对象之间不影响1
2
3SynchronizedExample1 example2 = new SynchronizedExample1();
example1.test2();
example2.test2();
3.修饰静态方法:作用于所有对象
同一时间只有一个线程可以执行,两个对象也是输出0~9,0~91
2
3
4
5public static synchronized void test2(int j) {
for (int i = 0; i < 10; i++) {
log.info("test2 {} - {}", j, i);
}
}
4.修饰类:作用于所有对象1
2
3
4
5
6
7public static void test1(int j) {
synchronized (SynchronizedExample2.class) {
for (int i = 0; i < 10; i++) {
log.info("test1 {} - {}", j, i);
}
}
}
Lock:依赖特殊的CPU指令 可中断unLock
竞争激烈维持常态
ReentrantLock
1 | private Lock bankLock = new ReentrantLock(); |
可见性:每个cpu都有cache
CPU2修改了内存中的a,CPU1读取a只读取cache中的值,不可见
虚拟机有两种模式 客户端模式不会优化 -server优化(64位虚拟机一般是server模式)
- 线程交叉执行
- 重排序+线程交叉执行
- 共享变量更新再工作内存和主存没同步
java内存模型
线程如何何时看到其它线程修改过的共享变量的值,如何同步地访问共享变量
堆 运行时动态分配内存大小。
调用栈和本地变量存放在线程栈。
java内存模型JMM对synchronized的两条规定:
- 线程解锁必须刷新共享变量到主存
- 线程加锁要清空工作内存中共享变量的值,使用共享变量时从主存读新值(同一个范围的锁)
volatile内存屏障,禁止重排序
volatile
写:会在写操作后加入一条store屏障指令它的修改会立刻刷新到主存,
图有问题???
读:读之前加入load屏障指令,c去内存中读取新值。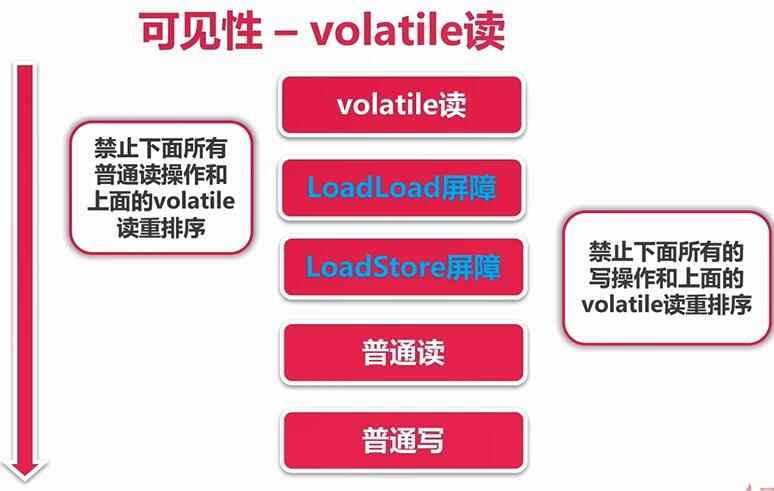
使用volatile run(){count++}还是会出错
volatile不具有原子性。
因为:1. 取值2. +1 3.写回主存,两个线程同时拿到值并+1,同时写回主存,丢1.
使用场景:对变量的写操作不依赖当前值
适合当状态标记量:用volatile的值作为线程1的状态加载完毕。线程2 while(!)判断
有序性
volatile、synchronized、Lock
不满足happends-beforey原则 JVM就可以重排序
volatile 写操作先于读操作
终止检测Thread.isAlive()