服务计算
http://act.buaa.edu.cn/hsun/SOC2016/index.html
偏态系数 和 峰态系数
中位数和均值的偏差,均值大叫正偏
分布集中强度,正太分布的峰态是3,如果有一个分布的峰态<1or>5则可以拒绝正太分布假设
三大分布
1.卡方分布:几个标准正太分布的平方和的分布
2.t分布:正太分布的随机变量/卡方分布的变量 用于小样本估计成正太分布方差未知的总体的均值
3.f分布:两个卡方分布的商
抽样误差
数据分类
定距(间隔)可以测量差值,但无绝对零点(温度)乘法,除法,比例是无意义的
判断正太分布
84.5%的样本比 均值-标准差 大
正太分布+-1倍标准差之间的累计值占69%,其它两边各占15.5%
如果偏态系数绝对值大(0.x),
极大似然
Preference 偏好
- Goal model
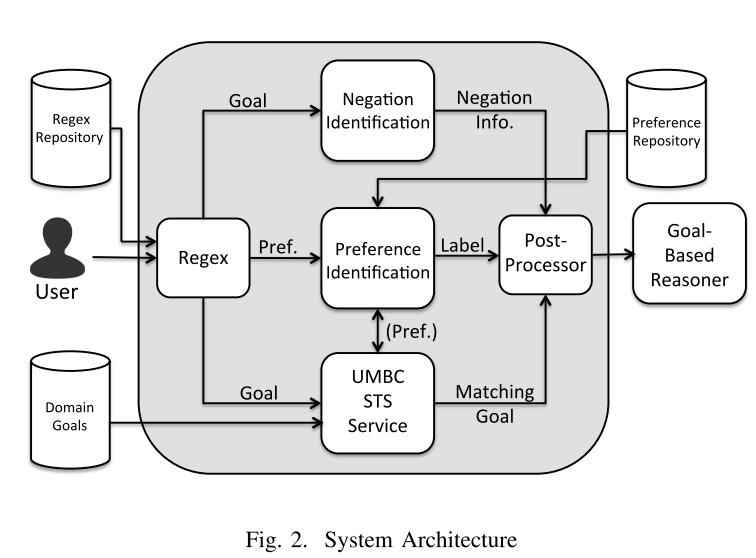
系统:自然语言偏好表达->用目标模型解释的正式的偏好说明。
组成: 正则、统计语义相似性,基于语料库的偏好强度分级。
目标:基于优先级的软件个性化定制接口。
流程推荐
流程结构相似度
- 相似度-> 目的:检索、合并、重组
计算流程相似度 计算优化
分解策略 聚合策略 mapreduce
建模【流程模型】: 用图 邻接矩阵、
流程模型:
- PTN:probabilistic time Petri net
流程信息
- 控制流、数据流、资源
- 流程文本、流程结构、流程语义
相似度方法
结构相似度
- MDS:matrix distance similarity
- MWT最小加权时间 方法->时间效率最高
- 图的编辑距离: greedyalgorithm、exhaustivealgorithm withpruning、processheuristicalgorithm、Astaralgorithm,其中平均性能最好的是 greedyalgorithm。
- 图挖掘算法:gSpan 频繁子图
流程相似度
- 执行轨迹 可达状态 因果关系
- 原则路径:根据流程结构可能发生的路径表示成一个集合 变迁系统(节点空间爆炸)
- 流程中的数据走向: 活动发生的概率。矩阵间距离
- 绝对值距离:非负、同一、对称、三角不等式->只比较部分对象
- 差异矩阵的所有元素
- 树的编辑距离
现状:基于图的相似度检测
复杂流程:
计算路径的相似度 匹配搜索的效率
并行!分解和合并得到拟合出来的相似度
与串行计算的准确度计算
编辑距离
(geeksforgeeks)[https://www.geeksforgeeks.org/dynamic-programming-set-5-edit-distance/]
1
2
3
4
5
6
7
8
9i=len(a);j=len(b);
d[i][j] 表示a转换成b的编辑距离
for (i = 0; i <= lena; i++) {
d[i][0] = i;
}
长度为j的字符串转换成长度为0的字符串最小步数。
for (j = 0; j <= lenb; j++) {
d[0][j] = j;
} 表示a[0]-a[j] ->""1
2
3
4
5
6(1)当a[i]==b[i],d[i][j]=d[i-1][j-1] // fxy -> fay 的编辑距离等于 fx -> fa
(2) 当≠,min(
<1> fxy -> fab 删除a[i] d[i-1][j]+1 fx->fab
<2> fxy -> fab 插入b[j] d[i][j-1]+1 fxyb->fab->(1)->fxy->fa
<3> fxy->fab 替换a[i]为b[j] d[i-1][j-1]->fxb->fab)
(3) 边界:a[i][0]=i
CART -> MARCH
- c->m t->c +H
- [] a
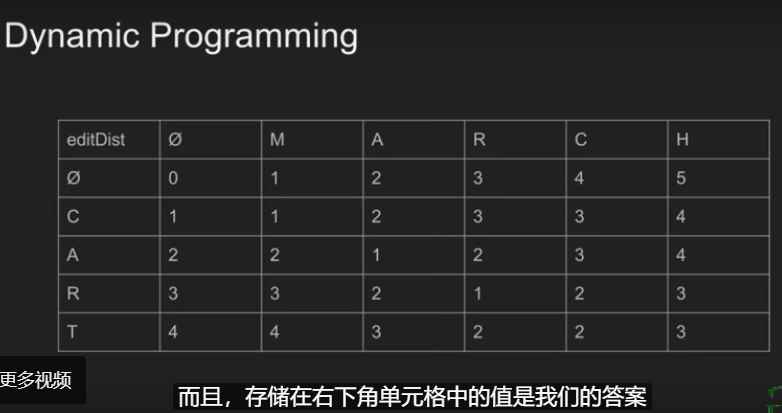
只需要d[i]一行