crowdedness 预测
随机森林
https://www.kaggle.com/nsrose7224/random-forest-regressor-accuracy-0-91
时间戳居中到中午12点1
2
3
4def time_to_seconds(time):
return time.hour * 3600 + time.minute * 60 + time.second
noon = time_to_seconds(time(12, 0, 0))
df.timestamp = df.timestamp.apply(lambda t: abs(noon - t))
时间序列星期/月/小时 编码
月变成1-12列,小时变成0-23列,星期变成0-6列1
2columns = ["day_of_week", "month", "hour"]
df = pd.get_dummies(df, columns=columns)
切分数据集,全部归一化1
2
3
4
5
6
7
8
9
10# Extract the training and test data
data = df.values
X = data[:, 1:] # all rows, no label
y = data[:, 0] # all rows, label only
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=42)
# Scale the data to be between -1 and 1
scaler = StandardScaler()
scaler.fit(X_train)
X_train = scaler.transform(X_train)
X_test = scaler.transform(X_test)
随机森林调参 并可视化R21
2
3
4
5
6
7
8
9
10estimators = np.arange(10, 200, 10)
scores = []
for n in estimators:
model.set_params(n_estimators=n)
model.fit(X_train, y_train)
scores.append(model.score(X_test, y_test))
plt.title("Effect of n_estimators")
plt.xlabel("n_estimator")
plt.ylabel("score")
plt.plot(estimators, scores)
估计总体的协方差矩阵(数据散点的形状估计)
https://scikit-learn.org/stable/modules/covariance.html
Empirical covariance 就是最大似然估计。只要数据量比特征量大很多
最大似然估计是总体协方差矩阵的无偏估计。(More precisely, the Maximum Likelihood Estimator of a sample is an unbiased estimator of the corresponding population’s covariance matrix.)
注意:训练集和测试集样本需要居中(均值一样):
参数assume_centered=False 则测试集应该和训练集有相同的平均值向量。
如果assume_centered=True 应该由用户居中。sklearn.preprocessing.StandardScaler(copy = True,with_mean = True,with_std = True ) with_mean 默认为True,在缩放之前对数据分布居中处理。
缺点:
可能因为数学原因不可逆?
empirical covariance matrix cannot be inverted for numerical reasons.
Shrunk Covariance
减小特征的最大值最小值的比率 或者对特征加上一个l2最大似然估计惩罚值。可以设定一个参数 bias/variance 参数 收缩是一个凸变换。
Ledoit-Wolf shrinkage
用来计算优化的收敛系数(上面的bias/variance)(?)
Oracle Approximating Shrinkage
比上面有更小的MSE
Sparse inverse covariance
用协方差矩阵的逆矩阵 如果两个条件独立则为0,用于学习,方差选择。
在数据集小的情况下,大概只有特征数量那么大或者更小,这个比Shrunk Covariance好。
而且这个能回复非对角数据。用GraphicalLasso 和GraphicalLassoCV 优化学习。
Robust Covariance Estimation
获得素数向量
1 | def sieve_eratosthenes(n): |
2xn向量 n个点坐标,求i到其他n-1个点的距离
1 | ## 所有城市到到当前城市的距离 |
pandas array根据index筛选,找到最小的标号
1 | def get_next_city(dist, avail): |
CountVectorizer 词袋模型
时间序列分解
R语言自带的AirPassengers
标记离群点
STL 根据稳健回归对时间序列数据进行分解,然后进行离群点识别。
STL: 基于局部甲醛回归的季节性趋势分解。
1 | > f<-stl(AirPassengers,"periodic",robust=TRUE) |
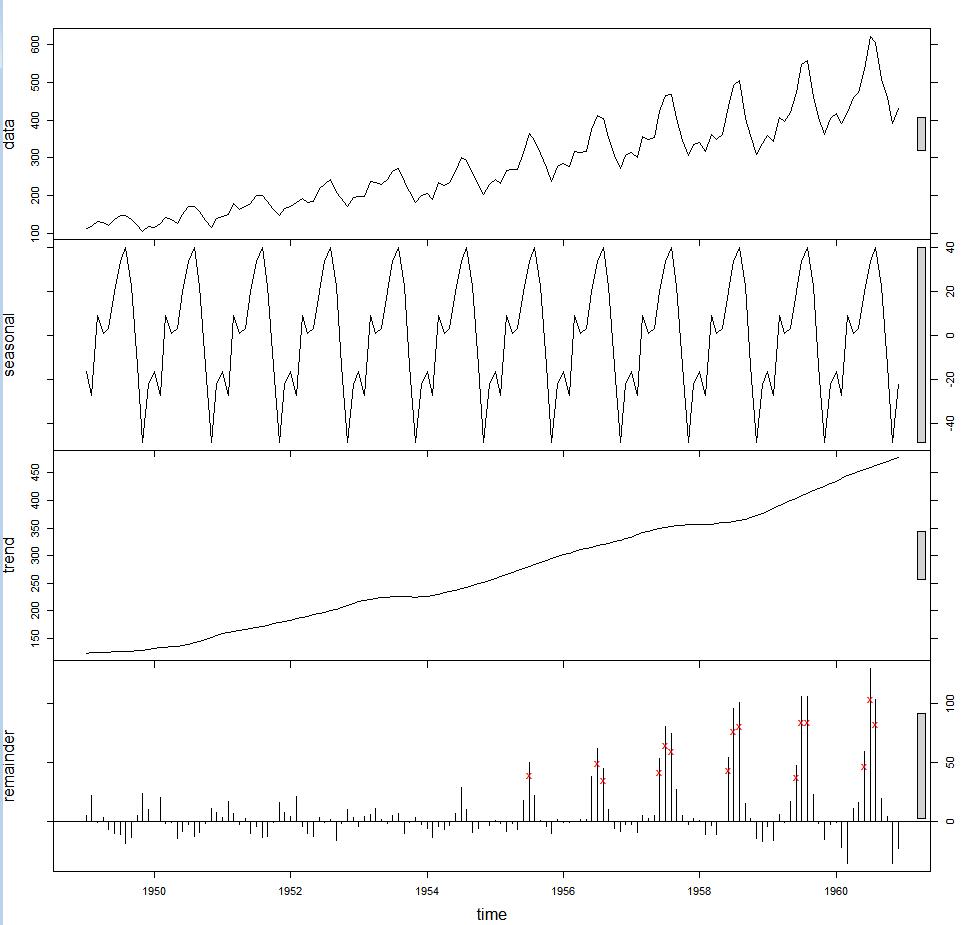
时间序列分解为 趋势、季节性、周期性以及不规则。
季节性成分1
2
3
4
5
6
7
8
9> plot(AirPassengers)
> apts<-ts(AirPassengers,frequency=12)
> f <- decompose(apts)
> f$figure
[1] -24.748737 -36.188131 -2.241162 -8.036616 -4.506313 35.402778
[7] 63.830808 62.823232 16.520202 -20.642677 -53.593434 -28.619949
> plot(f$figure,type="b",xaxt="n",xlab="")
> monthNames<-months(ISOdate(2011,1:12,1))
> axis(1,at=1:12,labels=monthNames,las=2)

分解 原图 趋势、季节性 不规则1
plot(f)
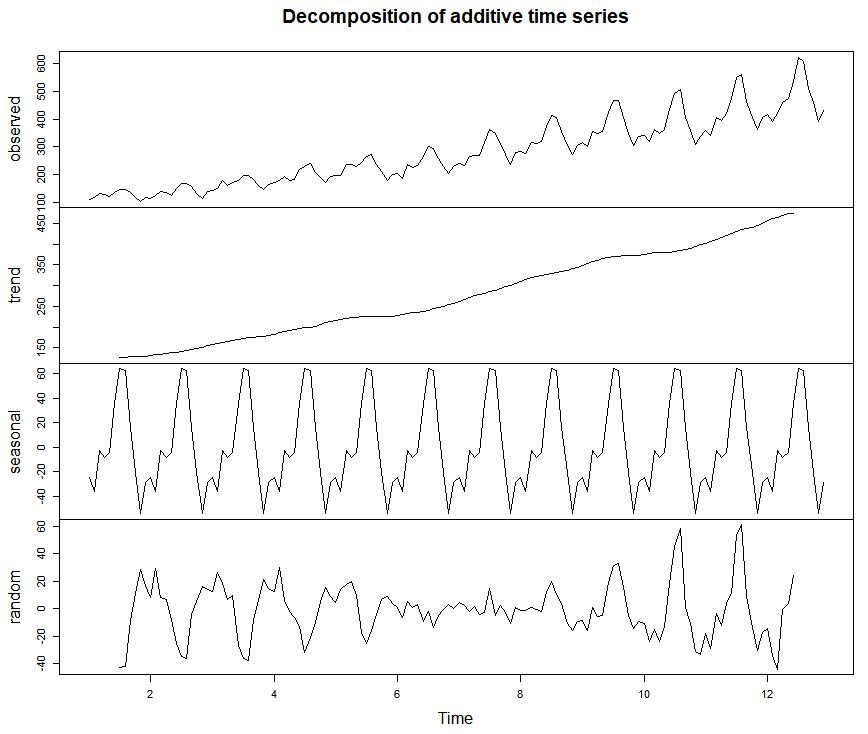
常用时间序列模型ARMA ARIMA
ARMA模型拟合: 许仙表示致信度水平95%下的误差边界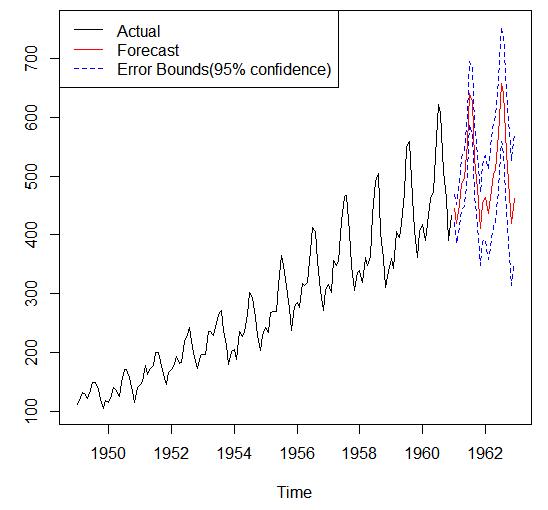
1 | > fit<-arima(AirPassengers,order=c(1,0,0),list(order=c(2,1,0),period=12)) |
时间序列聚类 DTW动态时间规整距离
foursquare category js提取
1 | fetch('https://api.foursquare.com/v2/venues/categories?v=20170211&oauth_token=QEJ4AQPTMMNB413HGNZ5YDMJSHTOHZHMLZCAQCCLXIX41OMP&includeSupportedCC=true') |
张量分解代码
http://tensorly.org/stable/user_guide/quickstart.html#tensor-decomposition
NMF的评价
basline用平均?
训练数据处理:
打乱样本1
2
3
4
5def _shuffle_data(self):
# [0,1,2,3,4,5] -> [5,3,2,4,0,1]
p = np.random.permutation(self._num_examples)
self._data = self._data[p]
self._labels = self._labels[p]
z-score标准化变成正太分布
原始值和平均值之间的距离,以标准差为单位计算。
相关性分析
散点矩阵 看是不是线性相关1
2data = pd.DataFrame(np.random.randn(200,4)*100,columns = ['A','B','C','D'])
pd.scatter_matrix(testUser,figsize = (8,5),c = 'k',marker='.',diagonal="hist",alpha=0.8,range_padding=.1)
https://blog.csdn.net/v_JULY_v/article/details/78121924
皮尔逊相关系数:服从正态分布的连续变量df.corr() 如果cosine相似度是0.97 pearson可能是1,与加减乘除无关,只看趋势。
使用之前先要检验是否正太分布p?0.05
Sperman相关系数:不正太分布的 等级相关系数,按rank计算
https://baike.baidu.com/item/%E7%9A%AE%E5%B0%94%E6%A3%AE%E7%9B%B8%E5%85%B3%E7%B3%BB%E6%95%B0
kaggle 方案索引
ARIMA网站流量预测
AR是autoregressive的缩写,表示自回归模型,含义是当前时间点的值等于过去若干个时间点的值的回归
I(d)将不平稳序列差分得到平稳序列,略过不表。假设我们现在的时间序列已经是平稳的了。
t时刻的值减去t-1时刻的值,得到新的时间序列称为1阶差分序列;1阶差分序列的1阶差分序列称为2阶差分序列
MA(q):MA是moving average的缩写,表示移动平均模型,含义是当前时间点的值等于过去若干个时间点的预测误差的回归;
1 日期数据变成week day 0的一组和week end 1的一组
2 用0,1当一列特征,总体趋势假设是1-28线性递增的一列 用一元线性回归拟合出两条曲线方程
得到预测流量的一列。
3 用4天做滑动平均一列
4 时间序列乘法分解模型 得到 实际值/移动平均列 = 周因素x波动
fix Effect Ramdom effect
KDE回归
https://rstudio-pubs-static.s3.amazonaws.com/238698_f5c485e2a4f2441dbc9a52ebda0fe8c0.html
http://nbviewer.jupyter.org/url/jakevdp.github.com/downloads/notebooks/KDEBench.ipynb
https://jakevdp.github.io/blog/2013/12/01/kernel-density-estimation/
推荐系统
- 全局流行度
- 分类模型
- 协同过滤
1)同现矩阵:每个格表示同时买了x物品和y物品的次数(是对称矩阵) 找一行里的最大几个做推荐
2)同现矩阵正规化,去除流行商品的影响
Jaccard相似度: 同时买i和j的人数/买i或j的人数
3)算上历史数据的加权平均 如果用户买过x和y商品,推荐z商品的分数是
1/2(matrix[x][z]+matrix[y][z]) 可以让最近购买的权重变大。对所有z商品排序,推荐最高的几个。
4)矩阵分解:从当前稀疏矩阵求L和R向量(回归问题) 填补缺失值
R描述物品 的所属 category 相关度向量
L用户对category的score向量
R x L 将所有R与一个用户L相乘取其中最大的几个推荐
https://software.intel.com/zh-cn/ai-academy/students/kits
动量梯度下降
vt 是之前梯度的均值,是梯度的积累值
之前积累的梯度方向是momentum step,当前梯度是gradient step,这次的更新梯度是actual step
1 模型刚开始 两个夹角小,则actual step 是2倍 可以加快训练
2 当梯度为0的时候 有动量
3 梯度改变方向 动量可以缓解动荡
卷积计算是对应位置相乘
每次卷积的输出size = 输入size - 卷积核size + 1
多个卷积层图像size变成1或者非整数 所以加padding。使输入和输出size一样。
每个通道独立做卷积,最后3个通道相加
P = 边距(padding)
S = 步长(stride)
输出尺寸:(n-p)/s + 1
参数数目 = kw x kh x ci x co
kw,kh 卷积核长宽
ci 输入通道数
co 输出通道数
池化 对应区域内的最大值 不用相乘
还有平均值池化 不是求对应区域最大值 而是求平均
步长和卷积核一样,每次移动的区域不重叠。不补0,不padding,多余的区域直接丢掉
没有用于求导的参数
池化层 参数为步长和池化核大小。
先池化 有利于减少图片大小 然后再卷积。
全连接层
输出展开成一维连接到下一层每个神经元上。 之后就不能做卷积、池化了,已经是一维的了
是普通神经网络的层
参数数目为 输入通道数目/输出通道数目
可以droupout 因为参数太多容易过拟合 随机丢掉几个不连接
相当于训练了子网络并且进行组合
激活函数
为什么激活函数不用线性函数?
因为高层和低层是全连接(参数矩阵W).
如果不用激活函数,相当于每个层次进行矩阵操作,深层神经网络也相当于单层
!!!todo混淆矩阵 准确度,精准率,召回率F1调和平均值,PR曲线ROC曲线
对于极度偏斜Skewed Data
正确率accuracy rate (TP+TN) / (TP+TN+FN+FP)
如果癌症概率只有0.1%
如果全部预测没病 就可以达到99.9%的准确率
1混淆矩阵 TF是真实值 PN是预测值1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26#真的不是
def TN(y_true,y_predict):
return np.sum((y_true==0)&(y_predict==0))
# 预测为1 错了
def FP(y_true,y_predict):
return np.sum((y_true==0)&(y_predict==1))
#其实是真的
def FN(y_true,y_predict):
return np.sum((y_true==1)&(y_predict==0))
#真的是真的
def TP(y_true,y_predict):
return np.sum((y_true==1)&(y_predict==1))
#混淆矩阵
def confusion_matrix(y_true,y_predict):
return np.array([
[TN(y_test,y_log_predict),FP(y_test,y_log_predict)],
[FN(y_test,y_log_predict),TP(y_test,y_log_predict)]
])
confusion_matrix(y_test,y_log_predict)
## 直接调库 顺序一样的
from sklearn.metrics import confusion_matrix
confusion_matrix(y_test,y_log_predict)
混淆矩阵可视化1
2
3from sklearn.metrics import confusion_matrix
confusion_matrix(y_test,y_predict)
plt.matshow(confusion_matrix(y_test,y_predict),cmap=plt.cm.gray)#越亮数字越大
2.精准率presision_score tp/(tp+fp)
//the ability of the classifier not to label as positive a sample
that is negative. 别把错的当对的的能力
应用场景:股票预测 精准率 对于FP敏感 对于上升的但是没有预测出来FN的漏掉了不是很在意
判断为刷单的用户里,真的是刷单的有多少 但是FN也是刷单的 漏判数据不在乎1
2
3
4
5
6
7def precision_score(y_true,y_predict):
tp = TP(y_test,y_log_predict)
fp = FP(y_test,y_log_predict)
return tp/(tp+fp)
## 直接调库
from sklearn.metrics import precision_score
precision_score(y_test,y_log_predict)
3.TPR 召回率recall_score tp/(tp+fn)
//he ability of the classifier to find all the positive samples.
找到所有正确的的能力(找全)
应用场景 : 医疗领域 召回率 希望所有有病的都要检查出来。FP没关系,即使没病说有病FN也没关系。1
2
3
4
5
6
7def recall_score(y_true,y_predict):
tp = TP(y_test,y_log_predict)
fn = FN(y_test,y_log_predict)
return tp/(tp+fn)
## 直接调库
from sklearn.metrics import recall_score
recall_score(y_test,y_log_predict)
4.F1调和平均值:两个不平衡的话很低,只有两个都很高才会高[0~1]1
2
3
4
5
6
7
8def F1(precision,recall):
try:
return 2*precision*recall/(precision+recall)
except:
return 0.0
## 直接调库
from sklxearn.metrics import f1_score
f1=f1_score(y_test,y_predict)
5.多分类的混淆矩阵
http://scikit-learn.org/stable/modules/generated/sklearn.metrics.recall_score.html
召回率和F值 : 计算所有的TP和FN再二值方法计算average : string, [None, ‘binary’ (default), ‘micro’, ‘macro’, ‘samples’, ‘weighted’]
binary 二值分类
micro
macro 不加权平均
5.PR曲线precision_recall_curve 用于比较两个模型和不同的超参数
threadholds?
6.
TPR == recall #真的是1/真实为1的所有预测
FPR 错误接受率FP/(FP+TN) # 多少正类被划分为负类的比例
FRR 错误拒绝率 FN/(TP+FN) # 多少正类没被判成正类1
2
3
4
5
6
7
8
9
10
11
12
13
14def TPR(y_true,y_predict):
tp = TP(y_true,y_predict)
fn = FN(y_true,y_predict)
try:
return tp/(tp+fn)
except:
return 0
def FPR(y_true,y_predict):#预测为1,预测错了 站真实值为0的百分比
fp = FP(y_true,y_predict)
tn = TN(y_true,y_predict)
try:
return fp/(fp+tn)
except:
return 0
7.ROC和AUC 用于确定predict概率的阈值
y_test = [0,1,0,0,0,1]
y_pre = [0.1,0.8,0.6…] 是概率值
确定一个阈值 超过才被判为正
ROC : x轴:FPR y轴:TPR
https://python3-cookbook.readthedocs.io/zh_CN/latest/c12/p01_start_stop_thread.html
python 二维list转置
星 解包1
2list(zip(*[[1,2],[3,4]]))
[(1, 3), (2, 4)]
list 平均值
1 | def averagenum(num): |
列求和
waitTime.apply(sum)
pandas 行求和
df['Col_sum'] = df.apply(lambda x: x.sum(), axis=1)
矩阵乘法
1 | a = np.array([[1,1],[1,0]]) |
standardscaler
(x-列均值)/ 列标准差
hausdorff距离
衡量2个点集的距离
度量了两个点集间的最大不匹配程度
location相关数据和数据处理
关于time/location 数据处理
https://www.kaggle.com/bqlearner/location-based-recommendation-system
Gowalla数据集:
https://snap.stanford.edu/data/loc-gowalla.html
垃圾短信分类 练习TODO
https://blog.csdn.net/github_36922345/article/details/53455401
pandas操作:
- 读csv多了一列unname
pd.read_csv("Osaka_user_localtime.csv",index_col=0)
1.userpd.columns=userpd.columns.droplevel([0,1])
2.df.set_index('date', inplace=True)列 ->索引
3.df['index'] = df.index,df.reset_index(level=0, inplace=True)
4.user_ca_ph.unstack(level=1)
5.去掉不用的复合索引user_ca_ph_cnt.columns=user_ca_ph_cnt.columns.droplevel([0,1])
6.填空user_ca_ph_cnt=user_ca_ph_cnt.fillna(0.)
7.train_data[["Age_int", "Survived"]].groupby(['Age_int'],as_index=False).mean()
8.找nullage_df_isnull = age_df.loc[(train_data['Age'].isnull())]
9.用dict替换掉一列1
2
3user_weight =[i/sum([30,53,334,16]) for i in [30,53,334,16]]
dict(zip(["Amusement","Entertainment","Historical","Park"],user_weight))
Osaka_cost["userweight"]=Osaka_cost["category"].map(usr_weight)
10.全部onehotpd.get_dummies(df)
11.离散化,分桶,再向量化/onehot1
2
3
4
5
6
7
8
9
10
11
12train_data['Fare_bin'] = pd.qcut(train_data['Fare'], 5)
0 (-0.001, 7.854]
1 (39.688, 512.329]
2 (7.854, 10.5]
3 (39.688, 512.329]
4 (7.854, 10.5]
# factorize
train_data['Fare_bin_id'] = pd.factorize(train_data['Fare_bin'])[0]
# dummies
fare_bin_dummies_df = pd.get_dummies(train_data['Fare_bin']).rename(columns=lambda x: 'Fare_' + str(x))
train_data = pd.concat([train_data, fare_bin_dummies_df], axis=1)
pip镜像
1 | pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pyclustering |
UTC 时间戳转localtime
1 | # 1346844688 -> 2012-09-05 11:31:28 |
标签传播LP算法(基于图)
1.半监督学习的假设:
1)Smoothness平滑假设:相似的数据具有相同的label。
2)Cluster聚类假设:处于同一个聚类下的数据具有相同label。
3)Manifold流形假设:处于同一流形结构下的数据具有相同label。
2.相似度矩阵
数据点为节点,包括labeled和unlabeled数据。边表示两点的相似度。
假设图是全连接.边ij的权重$W_{ij}=exp(\frac{-||x_i-x_j||^2}{α^2})$ α是超参。
另外可以构建KNN图 稀疏相似矩阵,指保留每个节点的k近邻权重,其它为0。
3.传播,权重越大传播概率越高
转移概率$P_{ij}=P(i->j)=\frac{w_{ij}}{\sum_{k=1}^nw_{ik}}$
- 假设C个类,L个labeled的样本,则LxC矩阵$Y_L$i行是第i个样本的标签指示向量。如果第i个样本类别是j,则
[i][j]为1,其它为0。 - 建立unlabeled的矩阵$Y_U$UxC同理。
- 合并得到NxC句矩阵。F=[Y_L;Y_U] (L+U=N行)保留样本i属于每个类别的概率。
4.算法步骤
- F=PF:每个节点以P的概率传播给其它节点。
- $F_L=Y_L$ (Y_L的标签是已知的,要保留,覆盖回原来的值)
- 重复以上两步直到F收敛。
5.优化算法。$F_L$部分是不变的.浪费的计算。
将概率转移矩阵变成
$$
P=\begin{bmatrix}
P_{LL} & P_{LU} \\
P_{UL} & P_{uU} \\
\end{bmatrix}
$$
只计算$F_U=P_{UU}F_U+P_{UL}Y_{L}$ 取决于无标签转移概率、有标签的相似度矩阵、无标签当前标签的转移概率。
算法可以优化成并行的,切分F_U
1. Logistic
损失函数L:单个训练样本
$\hat{y}=p(y=1|x)$ 给定样本x的条件下,输出y=1的概率
成本(cost)函数J:全体训练样本$\frac{1}{m}\sum_{i=1}^mL(\hat{y}^{(i)},y^{(i)})$
cost:每个样本的乘积的最大似然估计 *1/m
Logistic损失函数 $L(\hat{y},y) = -(ylog\hat{y}+(1-y)log(1-\hat{y}))$
- 当y=1,$L =-log\hat{y}$ 让误差最小,则让$\hat{y}$大,$\hat{y}$经过sigmoid小于1
- 当y=0,$L = -log(1-\hat{y})$,则$\hat{y}=0$
- 矩阵乘法:左向量组,列数是向量的维度;右线性空间;相乘:将向量组线性变换到新的线性空间。 右边的行数最少要满足由基地向量构成的线性空间维度。
- 特征向量:向量值发生了伸缩变换,没有旋转。伸缩比例是特征值。
- 梯度下降
$w=w-\alpha\frac{dJ(w,b)}{dw}$
$b=b-\alpha\frac{dJ(w,b)}{db}$ - 反向传播
计算loss对每个变量的梯度,通过链式法则 )
)
a=sigmoid($\hat{y}$)
正向传播:1.计算wx+b 2.经过sigmoid求出$\hat{y}$ 3.计算loss
反向传播:- da=loss对$\hat{y}$求导
- dz = da*sigmoid求导
- dw1 =dz*z对w1求导
- 向量化:不用一个for循环dcost = 1/m*np.sum(dz)
- 正向传播
1.$z=w^Tx+b$
2.np.dot(w.T,x)+b
3.$\hat{y}$=simgmoid(z) - 反向传播
4.$dz = \hat{y} - y$
5.dw = 1/m*np.dot(x,dz.T)
6.db = 1/m*np.sum(dz) - 梯度下降
7.w = w-αdw
8.b = b-αdb
以上for 梯度下降多少次
-创建一维向量不用要np.random.randn(5)因为a.shape=(5,)
用: 列向量np.random.randn(5,1);行向量np.random.randn(1,5) - 正向传播
2. 浅层NN
tanh是sigmoid的平移
tanh效果好因为 激活函数平均值接近0,tanh在所有场景几乎最优 不用sigmoid了
输出层用sigmoid:因为(0,1)之间的二分类问题
- tanh和sigmoid的问题是z很大时,梯度很小,梯度下降效率低
- $g’(tanh(z))=1-(tanh(z))^2$ ,$1-a^2$
- ReLu:修正线性单元(rectified linear unit):ReLU:= $a=max(0,z)$
- 只要z>0,导数=1;z<0,导数=0
除了输出层,都用ReLU为激活函数 - Leaky-ReLU:z<0时让导数不为零,有一个很小低梯度
max(0.01*z,z) - 虽然有一半导数=0,但因为有足够多的隐藏单元另z>0
- $g’=1 if z>0$
- 只要z>0,导数=1;z<0,导数=0
- 神经网络初始化:不能初始化为0,这样两个隐藏单元会相同。
$W^{[1]}$ = np.random.randn((2,2))0.01 使梯度较大
$b^{[1]}$ = np.zero((2,1))
$W^{[1]}$ = np.random.randn((2,2))0.01 - 二分类问题时da 最后一层
$L(a,y) = -(ylog(a)+(1-y)log(1-a))$
$da^{[1]} = -y/a + (1-y)/(1-a)$
bias偏差/variance方差
- high bias -> 欠拟合 ->选择新的网络直到至少可以拟合训练集
- high variance -> 过拟合 ->更多数据/正则化/回到1换模型
正则化- 高variance 过拟合
- L2正则:w通常是一个高维参数矢量已经可以表达high variance 问题
$+\frac{λ}2m||w||_2^2$ - L1正则:$\frac{λ}m||w||_1$ 使用
L1正则化,w最终会稀疏,w向量有很多0
Dropout随机失活 多用于图像
- a3 表示三层网络各节点的值, $a3=[a^{[1]},a^{[2]},a^{[3]}]$
- 权重转成0或1:d3=np.random.rand(a3.shape[0], a3.shape[1]) < keepProb
- 删除节点:a3 = np.multiply(a3, d3)
- 为了不影响原来Z的期望,a3 /= keepProb
- http://archive.ics.uci.edu/ml/
——最有名的机器学习数据资源来自美国加州大学欧文分校 - http://aws.amazon.com/publicdatasets/美国人口普查数据、人类基因组注释的数据\维基百科的页面流量\维基百科的链接数据
- http://www.data.gov——Data.gov启动于2009年,目的是使公众可以更加方便地访问政府的数据
flavor 中加时间向量,对每一个flavor进行时序预测,sum
flavor 有序字典
- 预测目标变量的值,则可以选择监督学习算法,需要进一步确定目标变量类型,如果目标变量是离散型,如是/否、1/2/3、A/B/C或者红/黄/黑等,则可以选择分类算法.
k-近邻算法 线性回归
朴素贝叶斯算法 局部加权线性回归
支持向量机 Ridge 回归
决策树 Lasso 最小回归系数估计
科学函数库SciPy和NumPy使用底层语言(C和Fortran)编写,提高了相关应用程序的计算性能。
8.1
- NumPy提供一个线性代数的库linalg,其中包含很多有用的函数。可以直接调用linalg.det()来计算行列式
第9章 用分类算法来处理回归问题
15 MapReduce:数值型和标称型数据。
- 过去100年国内最高气温:
每个mapper将产生一个温度,形如<”max”>,也就是所有的mapper都会产生相同的key:”max”字符串  )
)
集成算法
生成多个分类器再集成 全选分类器 求平均
pandas
- 时间序列关键点:极大值,极小值or拐点 用关键点代替原始时间序列。
- 合并关键点序列时间下标 得到等长序列
- Lance距离 无量纲。欧式距离缺点L:有量纲,变差大的变量在距离中贡献大。
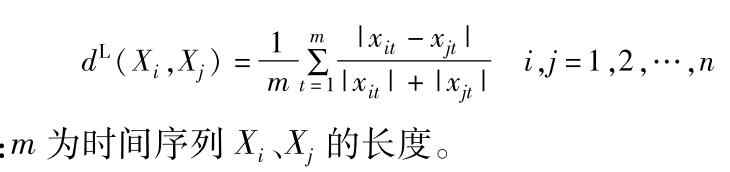
- FCM算法 每条时间序列属于各个类的程度。

ARIMA自回归综合移动平均
Auto-Regressive Integrated Moving Averages.
- Number of AR (Auto-Regressive) terms (p): 现在点使用多少个过往数据计算。
- Number of MA (Moving Average) terms (q):使用多少个过往的残余错误值。
- Number of Differences (d):非季节性的个数(小编:其实是否求导数)。
日期范围
- pd.date_range(‘4/1/2012’,’6/1/2022’) 默认按天
- pd.date_range(start=’4/1/2012’,periods=20)
- 每个月最后一个工作日 “BM”频率
pd.date_range(‘1/1/200’,’12/1/2000’,ferq=’BM’) - 规范化到午夜
- WOM日期 Week of Month freq=’WOM-3FRI’每月第3个星期五
5 时区
numpy
- random.rand(4,4) -> 4x4的 array
1
2arr_alice = arr[5:8]
arr_alice[0] =11
arr的值也会改变
np 的切片和赋值不会copy arr[5:8].copy()arr_alice = arr[5:8].copy()显示复制,arr不会被改变
- 多维数组 arr2d[0][2] == arr2d[0,2]
- np.random.randn(7,4)生成正态分布的随机数
names=='bob'[True,Fales] list,data[names=='bob]boolean数组可以用于索引data[-(names=='bob')]
花式索引
arr[[4,3,0,6]] 获取第4、3、0、6 行
array([1,2,3])
- from numpy import array
- list对应元素相乘:
某个向量沿着另一个向量的移动量。array(list)*array(list2)对应元素相乘 - .dtype 同构数据元素的类型
- zeros(10) ones(10) 全0or全1数组
- empty((2,3,2)) 创建没有任何具体值的数组
- np.dot(arr.T,arr) 内积
nonzero(array)
- nonzeros(a)返回数组a中值不为零(Flase)的元素的下标
- transpose([])转成array
- linspace(start,stop,num,endpoint=False)返回长为num的array 数值从start到stop渐变,endpoint=False递增
mat,matrix
1 | - from numpy import mat, matrix |
- 矩阵相乘:
矩阵相乘,multiply内积
`mat(list)mat(list2).T` 内积 from numpy import shape 查看矩阵or数组的维数
矩阵第一行元素jj[1,:]
矩阵对应元素相乘:矩阵相乘还可以看成是列的加权求和
矩阵相乘的MapReduce版本。??
from numpy import multiply1
2
3
4multiply(mat(list),mat(list2))
matrix([[ 2, 6, 12]])
array(list)*array(list2)
array([ 2, 6, 12])矩阵数组排序 .sort() 原地排序 结果占用原始存储空间
每个元素的排序序号:
1
2
3dd=mat([4, 5, 1])
dd.argsort()
matrix([[2, 0, 1]])数组/矩阵均值 .mean()
矩阵的逆.I
linalg.inv(A)
矩阵要可逆必须要是方阵。如果某个矩阵不可逆,则称它为奇异(singular)或退化(degenerate)矩阵。
- 一种方法是对矩阵进行重排然后每个元素除以行列式。如果行列式为0,就无逆矩阵。
mat()*mat().I≠1 计算机处理误差产生的结果
- 4×4的单位矩阵eye(4)/identity(4)
矩阵相关
- 行列式
det(A) - 秩 linalg.matrix_rank(A)
- 可逆矩阵求解
矩阵范数:
给向量赋予一个正标量值 到原点的距离
- L1:Manhattan distance。z=[3,4] $||z||_1=3+4=7$各元素绝对值之和
- 任意阶范数公式
)
- 二阶linalg.norm([8,1,6])
- 欧式距离
sqrt((v1-v2)*(v1-v2.T))- 曼哈顿距离
sum(abs(v1-v2))- 切比雪夫距离:国际象棋国王的步数
abs(v1-v2).max()
夹角cosθ
cos = dot(v1,v2)/(linalg.norm(v1)*linalg.norm(v2))
汉明距离
- 汉明距离:
shape(nonzero(v1-v2)[1])[0] - ?编辑距离:
A=”909”,B=”090”。A与B的汉明距离H(A, B) = 3,编辑距离ED(A, B) =2。 - ?文本相似度simHash
Jaccard(杰卡德) 集合 相似性系数:样本集交集与样本集并集的比值,即J = |A∩B| ÷ |A∪B|:两个文档的共同都有的词除以两个文档所有的词
- 杰卡德距离 1-J=(并-交)/并:
1
2import scipy.spatial.distance as dist
dist.pdist(mat,'jaccard')
相关系数 相关距离(线性相关)
coefficient 系数;1
2
3
4
5mv1= mean(mat[0])
mv2= mean(mat[1])
std1= std(mat[0])
std2= std(mat[1])
cor= mean(multiply(mat[0]-mv1,mat[1]-mv2))/(std1*std2)
马氏距离
- 协方差是对角阵、单位矩阵(两个样本向量之间独立同分布) 马氏距离为欧式距离
- 马氏距离 量纲无关
- 协方差矩阵的逆:
linalg.inv(cov(mat))
inv()矩阵求逆
- 协方差矩阵的逆:
- tp =mat.T[0]-mat.T[1]
dis = sqrt(dot(dot(tp,covinv),tp.T))
特征向量特征值
- evals(特征值),evecs(特征向量) = linalg.eig(mat)
?手工求特征值
1
2#求方程根
roots(A)还原矩阵 $A=Q∑Q^-1$
1
2
3#特征值构成的对角阵
sigma = 特征值*eye(m)
特征向量*sigma*linalg.inv(特征向量)
- 矩阵求导:
A向量(2·1)对B(3·1)求导,得到3·2的矩阵
model = ARIMA(ts_log, order=(2, 1, 2))
!qiudao
results_ARIMA = model.fit(disp=-1)
plt.plot(ts_log_diff)
plt.plot(results_ARIMA.fittedvalues, color=’red’)
plt.title(‘RSS: %.4f’% sum((results_ARIMA.fittedvalues-ts_log_diff)**2))
plt.show()
dic:key不存在,就会触发KeyError错误
{kind=link}
- 假设验证 实验结果是否有统计显著性或随机性
归一化:转换成无量纲
- 标准化后的值= (标准化前的值-分量的均值)/分量的标准差
- 标准化欧氏距离方差的倒数为权重的加权欧氏距离
1
2
3
4
5
6
7
8
9
10
11
12# 欧氏距离
mat([[1,2,3],[4,5,6]])
v12 = vmat[0]-vmat[1]
sqrt(v12*v12.T)
# 标准化
#1.方差
vstd = std(mat.T,axis=0)
#2.(标准化前的值-所有值的均值/方差
norm = (mat-mean(mat))/vstd.T
#3.欧式距离
normv12 = norm[0]-norm[1]
sqrt(normv12*nromv12.T)